Github Trending - Weekly
Github weekly trending
Interactive roadmaps, guides and other educational content to help developers grow in their careers.

roadmap.sh
Community driven roadmaps, articles and resources for developers
![]()
![]()
![]()
![]()

Roadmaps are now interactive, you can click the nodes to read more about the topics.
View all Roadmaps · Best Practices · Questions
Here is the list of available roadmaps with more being actively worked upon.
Have a look at the get started page that might help you pick up a path.
- Frontend Roadmap / Frontend Beginner Roadmap
- Backend Roadmap / Backend Beginner Roadmap
- DevOps Roadmap / DevOps Beginner Roadmap
- Full Stack Roadmap
- Git and GitHub
- API Design Roadmap
- Computer Science Roadmap
- Data Structures and Algorithms Roadmap
- AI and Data Scientist Roadmap
- AI Engineer Roadmap
- AWS Roadmap
- Cloudflare Roadmap
- Linux Roadmap
- Terraform Roadmap
- Data Analyst Roadmap
- MLOps Roadmap
- Product Manager Roadmap
- Engineering Manager Roadmap
- QA Roadmap
- Python Roadmap
- Software Architect Roadmap
- Game Developer Roadmap / Server Side Game Developer
- Software Design and Architecture Roadmap
- JavaScript Roadmap
- TypeScript Roadmap
- C++ Roadmap
- React Roadmap
- React Native Roadmap
- Vue Roadmap
- Angular Roadmap
- Node.js Roadmap
- PHP Roadmap
- GraphQL Roadmap
- Android Roadmap
- iOS Roadmap
- Flutter Roadmap
- Go Roadmap
- Rust Roadmap
- Java Roadmap
- Spring Boot Roadmap
- Design System Roadmap
- PostgreSQL Roadmap
- SQL Roadmap
- Redis Roadmap
- Blockchain Roadmap
- ASP.NET Core Roadmap
- System Design Roadmap
- Kubernetes Roadmap
- Cyber Security Roadmap
- MongoDB Roadmap
- UX Design Roadmap
- Docker Roadmap
- Prompt Engineering Roadmap
- Technical Writer Roadmap
- DevRel Engineer Roadmap
There are also interactive best practices:
- Backend Performance Best Practices
- Frontend Performance Best Practices
- Code Review Best Practices
- API Security Best Practices
- AWS Best Practices
..and questions to help you test, rate and improve your knowledge
Share with the community
Please consider sharing a post about roadmap.sh and the value it provides. It really does help!
Development
Clone the repository, install the dependencies and start the application
git clone [email protected]:kamranahmedse/developer-roadmap.git
cd developer-roadmap
npm install
npm run dev
Note: use the depth parameter to reduce the clone size and speed up the clone.
git clone --depth=1 https://github.com/kamranahmedse/developer-roadmap.git
Contribution
Have a look at contribution docs for how to update any of the roadmaps
- Add content to roadmaps
- Add new roadmaps
- Suggest changes to existing roadmaps
- Discuss ideas in issues
- Spread the word
Thanks to all contributors ❤
License
Have a look at the license file for details
Hydra is a game launcher with its own embedded bittorrent client
![]()
Hydra Launcher
Hydra is a game launcher with its own embedded bittorrent client.


![]()
![]()
![]()
![]()
![]()

Table of Contents
- Table of Contents
- About
- Features
- Installation
- Contributing
- Build from source
- Environment variables
- Running
- Build
- Contributors
- License
About
Hydra is a Game Launcher with its own embedded BitTorrent Client.
The launcher is written in TypeScript (Electron) and Python, which handles the torrenting system by using libtorrent.
Features
- Own embedded bittorrent client
- How Long To Beat (HLTB) integration on game page
- Downloads path customization
- Windows and Linux support
- Constantly updated
- And more ...
Installation
Follow the steps below to install:
- Download the latest version of Hydra from the Releases page.
- Download only .exe if you want to install Hydra on Windows.
- Download .deb or .rpm or .zip if you want to install Hydra on Linux. (depends on your Linux distro)
- Run the downloaded file.
- Enjoy Hydra!
Contributing
Join our Telegram
We concentrate our discussions on our Telegram channel.
Fork and clone your repository
- Fork the repository (click here to fork now)
- Clone your forked code
git clone https://github.com/your_username/hydra - Create a new branch
- Push your commits
- Submit a new Pull Request
Ways you can contribute
- Translation: We want Hydra to be available to as many people as possible. Feel free to help translate to new languages or update and improve the ones that are already available on Hydra.
- Code: Hydra is built with Typescript, Electron and a little bit of Python. If you want to contribute, join our Telegram!
Project Structure
- torrent-client: We use libtorrent, a Python library, to manage torrent downloads
- src/renderer: the UI of the application
- src/main: all the logic rests here.
Build from source
Install Node.js
Ensure you have Node.js installed on your machine. If not, download and install it from nodejs.org.
Install Yarn
Yarn is a package manager for Node.js. If you haven't installed Yarn yet, you can do so by following the instructions on yarnpkg.com.
Install Node Dependencies
Navigate to the project directory and install the Node dependencies using Yarn:
cd hydra
yarn
Install OpenSSL 1.1
OpenSSL 1.1 is required by libtorrent in Windows environments.
Install Python 3.9
Ensure you have Python 3.9 installed on your machine. You can download and install it from python.org.
Install Python Dependencies
Install the required Python dependencies using pip:
pip install -r requirements.txt
Environment variables
You'll need an SteamGridDB API Key in order to fetch the game icons on installation.
Once you have it, you can copy or rename the .env.example file to .env and put it onSTEAMGRIDDB_API_KEY.
Running
Once you've got all things set up, you can run the following command to start both the Electron process and the bittorrent client:
yarn dev
Build
Build the bittorrent client
Build the bittorrent client by using this command:
python torrent-client/setup.py build
Build the Electron application
Build the Electron application by using this command:
On Windows:
yarn build:win
On Linux:
yarn build:linux
Contributors
License
Hydra is licensed under the MIT License.
程序员在家做饭方法指南。Programmer's guide about how to cook at home (Simplified Chinese only).
程序员做饭指南
![]()




最近宅在家做饭,作为程序员,我偶尔在网上找找菜谱和做法。但是这些菜谱往往写法千奇百怪,经常中间莫名出来一些材料。对于习惯了形式语言的程序员来说极其不友好。
所以,我计划自己搜寻菜谱并结合实际做菜的经验,准备用更清晰精准的描述来整理常见菜的做法,以方便程序员在家做饭。
同样,我希望它是一个由社区驱动和维护的开源项目,使更多人能够一起做一个有趣的仓库。所以非常欢迎大家贡献它~
本地部署
如果需要在本地部署菜谱 Web 服务,可以在安装 Docker 后运行下面命令:
docker pull ghcr.io/anduin2017/how-to-cook:latest
docker run -d -p 5000:5000 ghcr.io/anduin2017/how-to-cook:latest
如需下载 PDF 版本,可以在浏览器中访问 /document.pdf
如何贡献
针对发现的问题,直接修改并提交 Pull request 即可。
在写新菜谱时,请复制并修改已有的菜谱模板: 示例菜。
搭建环境
菜谱
按难度索引
素菜
- 拔丝土豆
- 白灼菜心
- 包菜炒鸡蛋粉丝
- 菠菜炒鸡蛋
- 炒滑蛋
- 炒茄子
- 炒青菜
- 葱煎豆腐
- 脆皮豆腐
- 地三鲜
- 干锅花菜
- 蚝油三鲜菇
- 蚝油生菜
- 红烧冬瓜
- 红烧茄子
- 虎皮青椒
- 话梅煮毛豆
- 鸡蛋羹
- 微波炉鸡蛋羹
- 蒸箱鸡蛋羹
- 鸡蛋火腿炒黄瓜
- 茄子炖土豆
- 茭白炒肉
- 椒盐玉米
- 金针菇日本豆腐煲
- 烤茄子
- 榄菜肉末四季豆
- 雷椒皮蛋
- 凉拌黄瓜
- 凉拌木耳
- 凉拌莴笋
- 凉拌油麦菜
- 蒲烧茄子
- 芹菜拌茶树菇
- 陕北熬豆角
- 上汤娃娃菜
- 手撕包菜
- 水油焖蔬菜
- 松仁玉米
- 素炒豆角
- 酸辣土豆丝
- 糖拌西红柿
- 莴笋叶煎饼
- 西红柿炒鸡蛋
- 西红柿豆腐汤羹
- 西葫芦炒鸡蛋
- 小炒藕丁
- 洋葱炒鸡蛋
荤菜
- 巴基斯坦牛肉咖喱
- 白菜猪肉炖粉条
- 带把肘子
- 冬瓜酿肉
- 豆豉鲮鱼油麦菜
- 番茄红酱
- 粉蒸肉
- 干煸仔鸡
- 宫保鸡丁
- 咕噜肉
- 广式萝卜牛腩
- 贵州辣子鸡
- 荷兰豆炒腊肠
- 黑椒牛柳
- 简易红烧肉
- 南派红烧肉
- 红烧猪蹄
- 湖南家常红烧肉
- 黄瓜炒肉
- 黄焖鸡
- 徽派红烧肉
- 回锅肉
- 尖椒炒牛肉
- 尖叫牛蛙
- 姜炒鸡
- 姜葱捞鸡
- 酱牛肉
- 酱排骨
- 椒盐排条
- 芥末罗氏虾
- 咖喱肥牛
- 烤鸡翅
- 可乐鸡翅
- 口水鸡
- 辣椒炒肉
- 老妈蹄花
- 老式锅包肉
- 冷吃兔
- 荔枝肉
- 凉拌鸡丝
- 卤菜
- 萝卜炖羊排
- 麻辣香锅
- 麻婆豆腐
- 蚂蚁上树
- 梅菜扣肉
- 奶酪培根通心粉
- 牛排
- 农家一碗香
- 啤酒鸭
- 黔式腊肠娃娃菜
- 青椒土豆炒肉
- 清蒸鳜鱼
- 肉饼炖蛋
- 杀猪菜
- 山西过油肉
- 商芝肉
- 瘦肉土豆片
- 水煮牛肉
- 水煮肉片
- 蒜苔炒肉末
- 台式卤肉饭
- 糖醋里脊
- 糖醋排骨
- 甜辣烤全翅
- 土豆炖排骨
- 无骨鸡爪
- 西红柿牛腩
- 西红柿土豆炖牛肉
- 乡村啤酒鸭
- 香干芹菜炒肉
- 香干肉丝
- 香菇滑鸡
- 香煎五花肉
- 香辣鸡爪煲
- 湘祁米夫鸭
- 小炒黄牛肉
- 小炒鸡肝
- 小炒肉
- 小米辣炒肉
- 小酥肉
- 新疆大盘鸡
- 血浆鸭
- 羊排焖面
- 洋葱炒猪肉
- 意式烤鸡
- 鱼香茄子
- 鱼香肉丝
- 枝竹羊腩煲
- 猪皮冻
- 猪肉烩酸菜
- 柱候牛腩
- 孜然牛肉
- 醉排骨
水产
- 白灼虾
- 鳊鱼炖豆腐
- 蛏抱蛋
- 葱烧海参
- 葱油桂鱼
- 干煎阿根廷红虾
- 红烧鲤鱼
- 红烧鱼
- 红烧鱼头
- 黄油煎虾
- 烤鱼
- 芥末黄油罗氏虾
- 咖喱炒蟹
- 鲤鱼炖白菜
- 清蒸鲈鱼
- 清蒸生蚝
- 水煮鱼
- 蒜蓉虾
- 蒜香黄油虾
- 糖醋鲤鱼
- 微波葱姜黑鳕鱼
- 香煎翘嘴鱼
- 小龙虾
- 油焖大虾
早餐
- 茶叶蛋
- 蛋煎糍粑
- 桂圆红枣粥
- 鸡蛋三明治
- 煎饺
- 金枪鱼酱三明治
- 空气炸锅面包片
- 美式炒蛋
- 牛奶燕麦
- 手抓饼
- 水煮玉米
- 苏格兰蛋
- 太阳蛋
- 溏心蛋
- 吐司果酱
- 完美水煮蛋
- 微波炉蛋糕
- 微波炉荷包蛋
- 温泉蛋
- 燕麦鸡蛋饼
- 蒸花卷
- 蒸水蛋
主食
- 炒方便面
- 炒河粉
- 炒凉粉
- 炒馍
- 炒年糕
- 炒意大利面
- 蛋包饭
- 蛋炒饭
- 豆角焖面
- 韩式拌饭
- 河南蒸面条
- 火腿饭团
- 基础牛奶面包
- 茄子肉煎饼
- 鲣鱼海苔玉米饭
- 酱拌荞麦面
- 韭菜盒子
- 空气炸锅照烧鸡饭
- 醪糟小汤圆
- 老干妈拌面
- 老友猪肉粉
- 烙饼
- 凉粉
- 麻辣减脂荞麦面
- 麻油拌面
- 电饭煲蒸米饭
- 煮锅蒸米饭
- 披萨饼皮
- 热干面
- 日式肥牛丼饭
- 日式咖喱饭
- 肉蛋盖饭
- 芝麻烧饼
- 手工水饺
- 酸辣蕨根粉
- 汤面
- 微波炉腊肠煲仔饭
- 西红柿鸡蛋挂面
- 扬州炒饭
- 炸酱面
- 蒸卤面
- 中式馅饼
- 煮泡面加蛋
半成品加工
汤与粥
- 昂刺鱼豆腐汤
- 陈皮排骨汤
- 陈皮排骨汤
- 番茄牛肉蛋花汤
- 勾芡香菇汤
- 金针菇汤
- 菌菇炖乳鸽
- 腊八粥
- 罗宋汤
- 米粥
- 奶油蘑菇汤
- 排骨苦瓜汤
- 皮蛋瘦肉粥
- 生汆丸子汤
- 西红柿鸡蛋汤
- 小米粥
- 羊肉汤
- 银耳莲子粥
- 玉米排骨汤
- 紫菜蛋花汤
饮料
- 耙耙柑茶
- 百香果橙子特调
- 冰粉
- 菠萝咖啡特调
- 冬瓜茶
- 海边落日
- 金菲士
- 金汤力
- 可乐桶
- 奶茶
- 柠檬水
- 奇异果菠菜特调
- 砂糖椰子冰沙
- 酸梅汤
- 酸梅汤(半成品加工)
- 泰国手标红茶
- 杨枝甘露
- 长岛冰茶
- B52轰炸机
- Mojito莫吉托
酱料和其它材料
甜品
进阶知识学习
如果你已经做了许多上面的菜,对于厨艺已经入门,并且想学习更加高深的烹饪技巧,请继续阅读下面的内容:
A free and open source, self hosted Ai based live meeting note taker and minutes summary generator that can completely run in your Local device (Mac OS and windows OS Support added. Working on adding linux support soon) https://meetily.zackriya.com/

Meetily - AI-Powered Meeting Assistant
Open source Ai Assistant for taking meeting notes
Website • Author • Discord Channel
An AI-Powered Meeting Assistant that captures live meeting audio, transcribes it in real-time, and generates summaries while ensuring user privacy. Perfect for teams who want to focus on discussions while automatically capturing and organizing meeting content without the need for external servers or complex infrastructure.
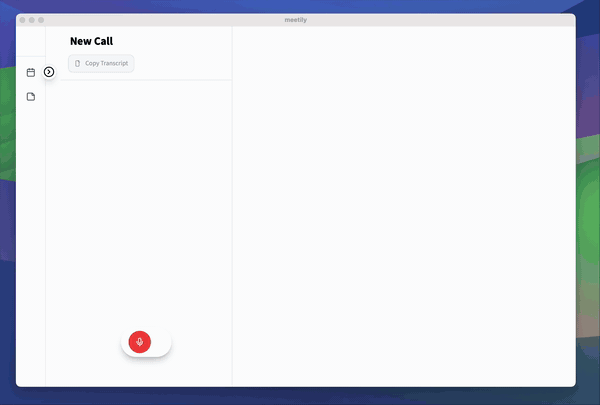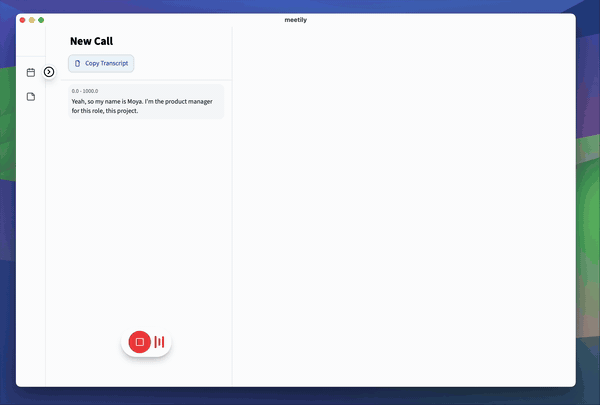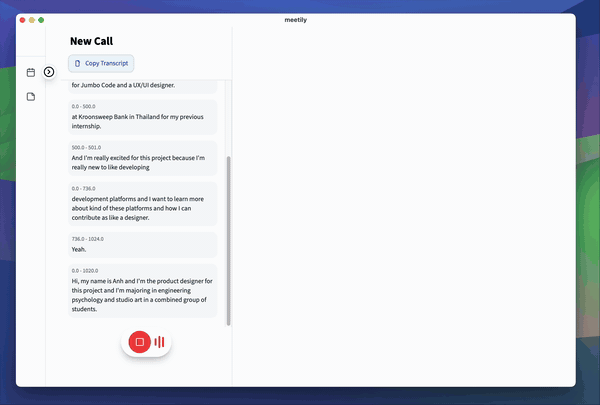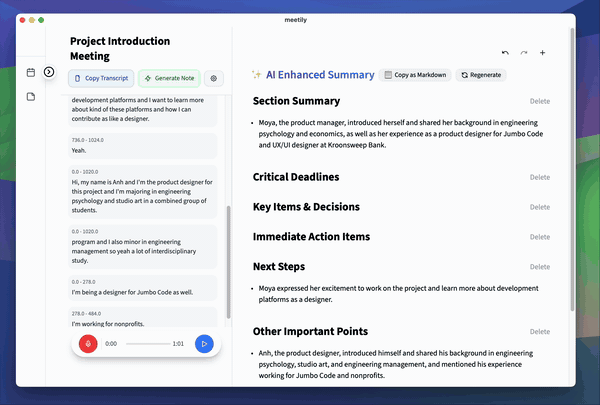
Overview
An AI-powered meeting assistant that captures live meeting audio, transcribes it in real-time, and generates summaries while ensuring user privacy. Perfect for teams who want to focus on discussions while automatically capturing and organizing meeting content.
Why?
While there are many meeting transcription tools available, this solution stands out by offering:
- Privacy First: All processing happens locally on your device
- Cost Effective: Uses open-source AI models instead of expensive APIs
- Flexible: Works offline, supports multiple meeting platforms
- Customizable: Self-host and modify for your specific needs
- Intelligent: Built-in knowledge graph for semantic search across meetings
Features
✅ Modern, responsive UI with real-time updates
✅ Real-time audio capture (microphone + system audio)
✅ Live transcription using Whisper.cpp
🚧 Speaker diarization
✅ Local processing for privacy
✅ Packaged the app for macOS and Windows
🚧 Export to Markdown/PDF
Note: We have a Rust-based implementation that explores better performance and native integration. It currently implements:
- ✅ Real-time audio capture from both microphone and system audio
- ✅ Live transcription using locally-running Whisper
- ✅ Speaker diarization
- ✅ Rich text editor for notes
We are currently working on:
- ✅ Export to Markdown/PDF
- ✅ Export to HTML
Release 0.0.3
A new release is available!
Please check out the release here.
What's New
- Windows Support: Fixed audio capture issues on Windows
- Improved Error Handling: Better error handling and logging for audio devices
- Enhanced Device Detection: More robust audio device detection across platforms
- Windows Installers: Added both .exe and .msi installers for Windows
- Transcription quality is improved
- Bug fixes and improvements for frontend
- Better backend app build process
- Improved documentation
What would be next?
- Database connection to save meeting minutes
- Improve summarization quality for smaller LLM models
- Add download options for meeting transcriptions
- Add download option for summary
Known issues
- Smaller LLMs can hallucinate, making summarization quality poor; Please use model above 32B parameter size
- Backend build process requires CMake, C++ compiler, etc. Making it harder to build
- Backend build process requires Python 3.10 or newer
- Frontend build process requires Node.js
LLM Integration
The backend supports multiple LLM providers through a unified interface. Current implementations include:
Supported Providers
- Anthropic (Claude models)
- Groq (Llama3.2 90 B)
- Ollama (Local models that supports function calling)
Configuration
Create .env file with your API keys:
# Required for Anthropic
ANTHROPIC_API_KEY=your_key_here
# Required for Groq
GROQ_API_KEY=your_key_here
System Architecture
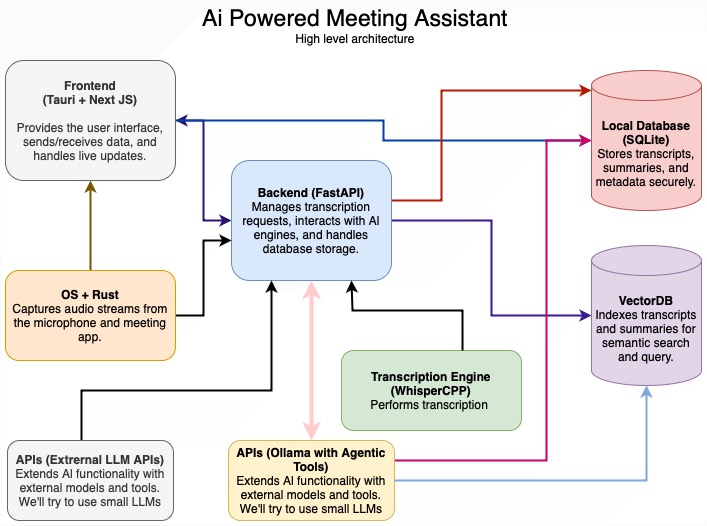
Core Components
-
Audio Capture Service
- Real-time microphone/system audio capture
- Audio preprocessing pipeline
- Built with Rust (experimental) and Python
-
Transcription Engine
- Whisper.cpp for local transcription
- Supports multiple model sizes (tiny->large)
- GPU-accelerated processing
-
LLM Orchestrator
- Unified interface for multiple providers
- Automatic fallback handling
- Chunk processing with overlap
- Model configuration:
-
Data Services
- ChromaDB: Vector store for transcript embeddings
- SQLite: Process tracking and metadata storage
-
API Layer
- FastAPI endpoints:
- POST /upload
- POST /process
- GET /summary/{id}
- DELETE /summary/{id}
- FastAPI endpoints:
Deployment Architecture
- Frontend: Tauri app + Next.js (packaged executables)
- Backend: Python FastAPI:
- Transcript workers
- LLM inference
Prerequisites
- Node.js 18+
- Python 3.10+
- FFmpeg
- Rust 1.65+ (for experimental features)
- Cmake 3.22+ (for building the frontend)
- For Windows: Visual Studio Build Tools with C++ development workload
Setup Instructions
1. Frontend Setup
Run packaged version
Go to the releases page and download the latest version.
For Windows:
- Download either the
.exeinstaller or.msipackage - Once the installer is downloaded, double-click the executable file to run it
- Windows will ask if you want to run untrusted apps, click "More info" and choose "Run anyway"
- Follow the installation wizard to complete the setup
- The application will be installed and available on your desktop
For macOS:
- Download the
dmg_darwin_arch64.zipfile - Extract the file
- Double-click the
.dmgfile inside the extracted folder - Drag the application to your Applications folder
- Execute the following command in terminal to remove the quarantine attribute:
xattr -c /Applications/meeting-minutes-frontend.app
Provide necessary permissions for audio capture and microphone access.
Dev run
# Navigate to frontend directory
cd frontend
# Give execute permissions to clean_build.sh
chmod +x clean_build.sh
# run clean_build.sh
./clean_build.sh
2. Backend Setup
# Clone the repository
git clone https://github.com/Zackriya-Solutions/meeting-minutes.git
cd meeting-minutes/backend
# Create and activate virtual environment
# On macOS/Linux:
python -m venv venv
source venv/bin/activate
# On Windows:
python -m venv venv
.\venv\Scripts\activate
# Install dependencies
pip install -r requirements.txt
# Add environment file with API keys
# On macOS/Linux:
echo -e "ANTHROPIC_API_KEY=your_api_key\nGROQ_API_KEY=your_api_key" | tee .env
# On Windows (PowerShell):
"ANTHROPIC_API_KEY=your_api_key`nGROQ_API_KEY=your_api_key" | Out-File -FilePath .env -Encoding utf8
# Configure environment variables for Groq
# On macOS/Linux:
export GROQ_API_KEY=your_groq_api_key
# On Windows (PowerShell):
$env:GROQ_API_KEY="your_groq_api_key"
# Build dependencies
# On macOS/Linux:
chmod +x build_whisper.sh
./build_whisper.sh
# On Windows:
.\build_whisper.bat
# Start backend servers
# On macOS/Linux:
./clean_start_backend.sh
# On Windows:
.\start_with_output.ps1
Development Guidelines
- Follow the established project structure
- Write tests for new features
- Document API changes
- Use type hints in Python code
- Follow ESLint configuration for JavaScript/TypeScript
Contributing
- Fork the repository
- Create a feature branch
- Submit a pull request
License
MIT License - Feel free to use this project for your own purposes.
Introducing Subscription
We are planning to add a subscription option so that you don't have to run the backend on your own server. This will help you scale better and run the service 24/7. This is based on a few requests we received. If you are interested, please fill out the form here.
Last updated: March 3, 2025
Star History
An AI Hedge Fund Team
AI Hedge Fund
This is a proof of concept for an AI-powered hedge fund. The goal of this project is to explore the use of AI to make trading decisions. This project is for educational purposes only and is not intended for real trading or investment.
This system employs several agents working together:
- Ben Graham Agent - The godfather of value investing, only buys hidden gems with a margin of safety
- Bill Ackman Agent - An activist investors, takes bold positions and pushes for change
- Cathie Wood Agent - The queen of growth investing, believes in the power of innovation and disruption
- Charlie Munger Agent - Warren Buffett's partner, only buys wonderful businesses at fair prices
- Michael Burry Agent - The Big Short contrarian who hunts for deep value
- Peter Lynch Agent - Practical investor who seeks "ten-baggers" in everyday businesses
- Phil Fisher Agent - Meticulous growth investor who uses deep "scuttlebutt" research
- Stanley Druckenmiller Agent - Macro legend who hunts for asymmetric opportunities with growth potential
- Warren Buffett Agent - The oracle of Omaha, seeks wonderful companies at a fair price
- Valuation Agent - Calculates the intrinsic value of a stock and generates trading signals
- Sentiment Agent - Analyzes market sentiment and generates trading signals
- Fundamentals Agent - Analyzes fundamental data and generates trading signals
- Technicals Agent - Analyzes technical indicators and generates trading signals
- Risk Manager - Calculates risk metrics and sets position limits
- Portfolio Manager - Makes final trading decisions and generates orders
Note: the system simulates trading decisions, it does not actually trade.

Disclaimer
This project is for educational and research purposes only.
- Not intended for real trading or investment
- No warranties or guarantees provided
- Past performance does not indicate future results
- Creator assumes no liability for financial losses
- Consult a financial advisor for investment decisions
By using this software, you agree to use it solely for learning purposes.
Table of Contents
Setup
Using Poetry
Clone the repository:
git clone https://github.com/virattt/ai-hedge-fund.git
cd ai-hedge-fund
- Install Poetry (if not already installed):
curl -sSL https://install.python-poetry.org | python3 -
- Install dependencies:
poetry install
- Set up your environment variables:
# Create .env file for your API keys
cp .env.example .env
- Set your API keys:
# For running LLMs hosted by openai (gpt-4o, gpt-4o-mini, etc.)
# Get your OpenAI API key from https://platform.openai.com/
OPENAI_API_KEY=your-openai-api-key
# For running LLMs hosted by groq (deepseek, llama3, etc.)
# Get your Groq API key from https://groq.com/
GROQ_API_KEY=your-groq-api-key
# For getting financial data to power the hedge fund
# Get your Financial Datasets API key from https://financialdatasets.ai/
FINANCIAL_DATASETS_API_KEY=your-financial-datasets-api-key
Using Docker
-
Make sure you have Docker installed on your system. If not, you can download it from Docker's official website.
-
Clone the repository:
git clone https://github.com/virattt/ai-hedge-fund.git
cd ai-hedge-fund
- Set up your environment variables:
# Create .env file for your API keys
cp .env.example .env
-
Edit the .env file to add your API keys as described above.
-
Build the Docker image:
# On Linux/Mac:
./run.sh build
# On Windows:
run.bat build
Important: You must set OPENAI_API_KEY, GROQ_API_KEY, ANTHROPIC_API_KEY, or DEEPSEEK_API_KEY for the hedge fund to work. If you want to use LLMs from all providers, you will need to set all API keys.
Financial data for AAPL, GOOGL, MSFT, NVDA, and TSLA is free and does not require an API key.
For any other ticker, you will need to set the FINANCIAL_DATASETS_API_KEY in the .env file.
Usage
Running the Hedge Fund
With Poetry
poetry run python src/main.py --ticker AAPL,MSFT,NVDA
With Docker
# On Linux/Mac:
./run.sh --ticker AAPL,MSFT,NVDA main
# On Windows:
run.bat --ticker AAPL,MSFT,NVDA main
Example Output:
You can also specify a --ollama flag to run the AI hedge fund using local LLMs.
# With Poetry:
poetry run python src/main.py --ticker AAPL,MSFT,NVDA --ollama
# With Docker (on Linux/Mac):
./run.sh --ticker AAPL,MSFT,NVDA --ollama main
# With Docker (on Windows):
run.bat --ticker AAPL,MSFT,NVDA --ollama main
You can also specify a --show-reasoning flag to print the reasoning of each agent to the console.
# With Poetry:
poetry run python src/main.py --ticker AAPL,MSFT,NVDA --show-reasoning
# With Docker (on Linux/Mac):
./run.sh --ticker AAPL,MSFT,NVDA --show-reasoning main
# With Docker (on Windows):
run.bat --ticker AAPL,MSFT,NVDA --show-reasoning main
You can optionally specify the start and end dates to make decisions for a specific time period.
# With Poetry:
poetry run python src/main.py --ticker AAPL,MSFT,NVDA --start-date 2024-01-01 --end-date 2024-03-01
# With Docker (on Linux/Mac):
./run.sh --ticker AAPL,MSFT,NVDA --start-date 2024-01-01 --end-date 2024-03-01 main
# With Docker (on Windows):
run.bat --ticker AAPL,MSFT,NVDA --start-date 2024-01-01 --end-date 2024-03-01 main
Running the Backtester
With Poetry
poetry run python src/backtester.py --ticker AAPL,MSFT,NVDA
With Docker
# On Linux/Mac:
./run.sh --ticker AAPL,MSFT,NVDA backtest
# On Windows:
run.bat --ticker AAPL,MSFT,NVDA backtest
Example Output:
You can optionally specify the start and end dates to backtest over a specific time period.
# With Poetry:
poetry run python src/backtester.py --ticker AAPL,MSFT,NVDA --start-date 2024-01-01 --end-date 2024-03-01
# With Docker (on Linux/Mac):
./run.sh --ticker AAPL,MSFT,NVDA --start-date 2024-01-01 --end-date 2024-03-01 backtest
# With Docker (on Windows):
run.bat --ticker AAPL,MSFT,NVDA --start-date 2024-01-01 --end-date 2024-03-01 backtest
You can also specify a --ollama flag to run the backtester using local LLMs.
# With Poetry:
poetry run python src/backtester.py --ticker AAPL,MSFT,NVDA --ollama
# With Docker (on Linux/Mac):
./run.sh --ticker AAPL,MSFT,NVDA --ollama backtest
# With Docker (on Windows):
run.bat --ticker AAPL,MSFT,NVDA --ollama backtest
Project Structure
ai-hedge-fund/
├── src/
│ ├── agents/ # Agent definitions and workflow
│ │ ├── bill_ackman.py # Bill Ackman agent
│ │ ├── fundamentals.py # Fundamental analysis agent
│ │ ├── portfolio_manager.py # Portfolio management agent
│ │ ├── risk_manager.py # Risk management agent
│ │ ├── sentiment.py # Sentiment analysis agent
│ │ ├── technicals.py # Technical analysis agent
│ │ ├── valuation.py # Valuation analysis agent
│ │ ├── ... # Other agents
│ │ ├── warren_buffett.py # Warren Buffett agent
│ ├── tools/ # Agent tools
│ │ ├── api.py # API tools
│ ├── backtester.py # Backtesting tools
│ ├── main.py # Main entry point
├── pyproject.toml
├── ...
Contributing
- Fork the repository
- Create a feature branch
- Commit your changes
- Push to the branch
- Create a Pull Request
Important: Please keep your pull requests small and focused. This will make it easier to review and merge.
Feature Requests
If you have a feature request, please open an issue and make sure it is tagged with enhancement.
License
This project is licensed under the MIT License - see the LICENSE file for details.
An AI web browsing framework focused on simplicity and extensibility.
The production-ready framework for AI browser automations.
Read the Docs
Why Stagehand?
Most existing browser automation tools either require you to write low-level code in a framework like Selenium, Playwright, or Puppeteer, or use high-level agents that can be unpredictable in production. By letting developers choose what to write in code vs. natural language, Stagehand is the natural choice for browser automations in production.
-
Choose when to write code vs. natural language: use AI when you want to navigate unfamiliar pages, and use code (Playwright) when you know exactly what you want to do.
-
Preview and cache actions: Stagehand lets you preview AI actions before running them, and also helps you easily cache repeatable actions to save time and tokens.
-
Computer use models with one line of code: Stagehand lets you integrate SOTA computer use models from OpenAI and Anthropic into the browser with one line of code.
Example
Here's how to build a sample browser automation with Stagehand:
// Use Playwright functions on the page object
const page = stagehand.page;
await page.goto("https://github.com/browserbase");
// Use act() to execute individual actions
await page.act("click on the stagehand repo");
// Use Computer Use agents for larger actions
const agent = stagehand.agent({
provider: "openai",
model: "computer-use-preview",
});
await agent.execute("Get to the latest PR");
// Use extract() to read data from the page
const { author, title } = await page.extract({
instruction: "extract the author and title of the PR",
schema: z.object({
author: z.string().describe("The username of the PR author"),
title: z.string().describe("The title of the PR"),
}),
});
Documentation
Visit docs.stagehand.dev to view the full documentation.
Getting Started
Start with Stagehand with one line of code, or check out our Quickstart Guide for more information:
npx create-browser-app

Build and Run from Source
git clone https://github.com/browserbase/stagehand.git
cd stagehand
npm install
npx playwright install
npm run build
npm run example # run the blank script at ./examples/example.ts
Stagehand is best when you have an API key for an LLM provider and Browserbase credentials. To add these to your project, run:
cp .env.example .env
nano .env # Edit the .env file to add API keys
Contributing
[!NOTE]
We highly value contributions to Stagehand! For questions or support, please join our Slack community.
At a high level, we're focused on improving reliability, speed, and cost in that order of priority. If you're interested in contributing, we strongly recommend reaching out to Anirudh Kamath or Paul Klein in our Slack community before starting to ensure that your contribution aligns with our goals.
For more information, please see our Contributing Guide.
Acknowledgements
This project heavily relies on Playwright as a resilient backbone to automate the web. It also would not be possible without the awesome techniques and discoveries made by tarsier, gemini-zod, and fuji-web.
We'd like to thank the following people for their major contributions to Stagehand:
- Paul Klein
- Anirudh Kamath
- Sean McGuire
- Miguel Gonzalez
- Sameel Arif
- Filip Michalsky
- Jeremy Press
- Navid Pour
License
Licensed under the MIT License.
Copyright 2025 Browserbase, Inc.
PDF scientific paper translation with preserved formats - 基于 AI 完整保留排版的 PDF 文档全文双语翻译,支持 Google/DeepL/Ollama/OpenAI 等服务,提供 CLI/GUI/MCP/Docker/Zotero



PDF scientific paper translation and bilingual comparison.
- 📊 Preserve formulas, charts, table of contents, and annotations (preview).
- 🌐 Support multiple languages, and diverse translation services.
- 🤖 Provides commandline tool, interactive user interface, and Docker
Feel free to provide feedback in GitHub Issues or Telegram Group.
For details on how to contribute, please consult the Contribution Guide.
Updates
- [Mar. 3, 2025] Experimental support for the new backend BabelDOC WebUI added as an experimental option (by @awwaawwa)
- [Feb. 22 2025] Better release CI and well-packaged windows-amd64 exe (by @awwaawwa)
- [Dec. 24 2024] The translator now supports local models on Xinference (by @imClumsyPanda)
- [Dec. 19 2024] Non-PDF/A documents are now supported using
-cp(by @reycn) - [Dec. 13 2024] Additional support for backend by (by @YadominJinta)
- [Dec. 10 2024] The translator now supports OpenAI models on Azure (by @yidasanqian)
Preview

Online Service 🌟
You can try our application out using either of the following demos:
- Public free service online without installation (recommended).
- Immersive Translate - BabelDOC 1000 free pages per month. (recommended)
- Demo hosted on HuggingFace
- Demo hosted on ModelScope without installation.
Note that the computing resources of the demo are limited, so please avoid abusing them.
Installation and Usage
Methods
For different use cases, we provide distinct methods to use our program:
1. UV install
-
Python installed (3.10 <= version <= 3.12)
-
Install our package:
pip install uv uv tool install --python 3.12 pdf2zh -
Execute translation, files generated in current working directory:
pdf2zh document.pdf
2. Windows exe
-
Download pdf2zh-version-win64.zip from release page
-
Unzip and double-click
pdf2zh.exeto run.
3. Graphic user interface
1. Python installed (3.10 <= version <= 3.12) 2. Install our package:pip install pdf2zh
-
Start using in browser:
pdf2zh -i -
If your browswer has not been started automatically, goto
http://localhost:7860/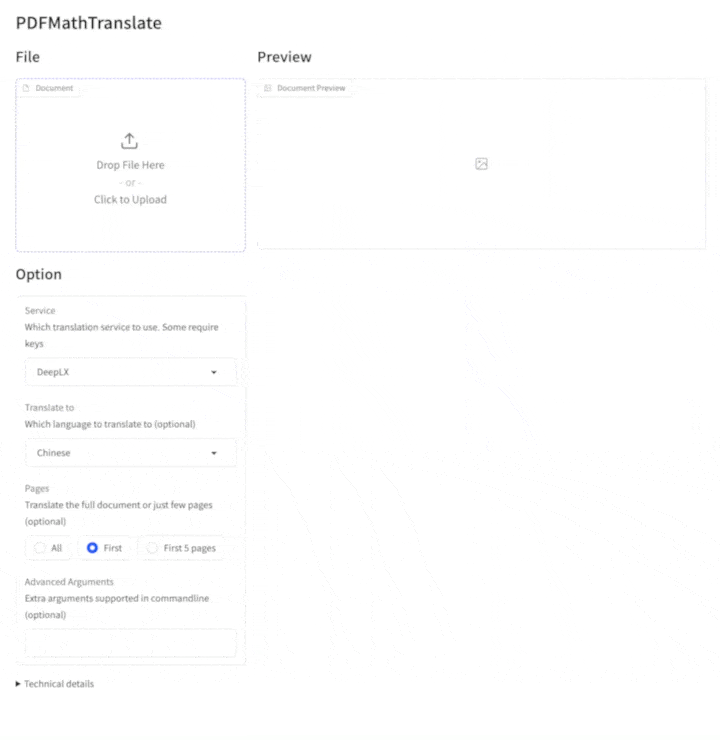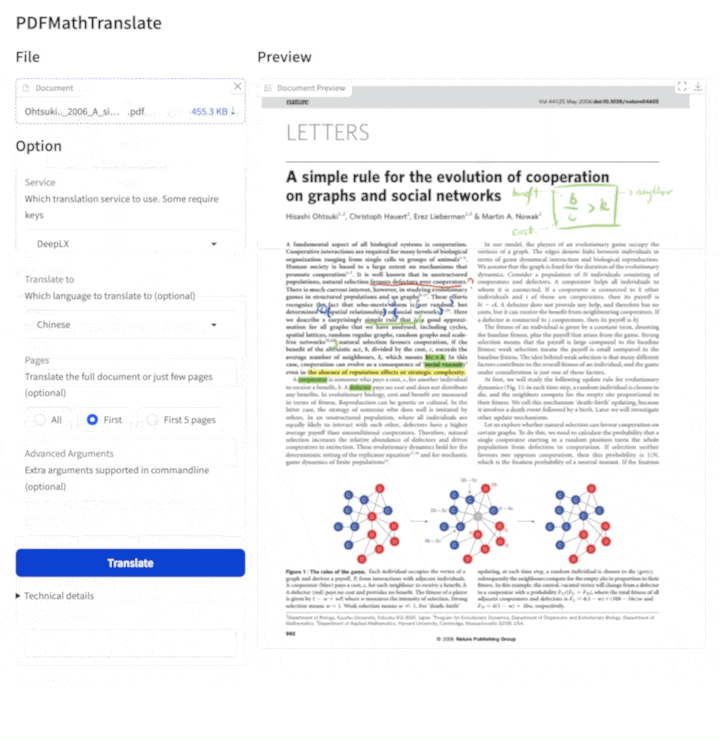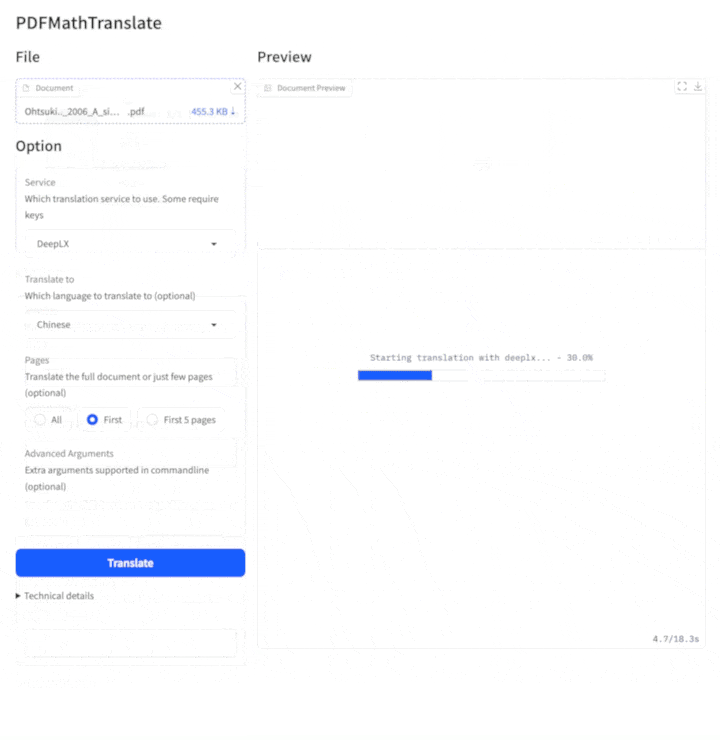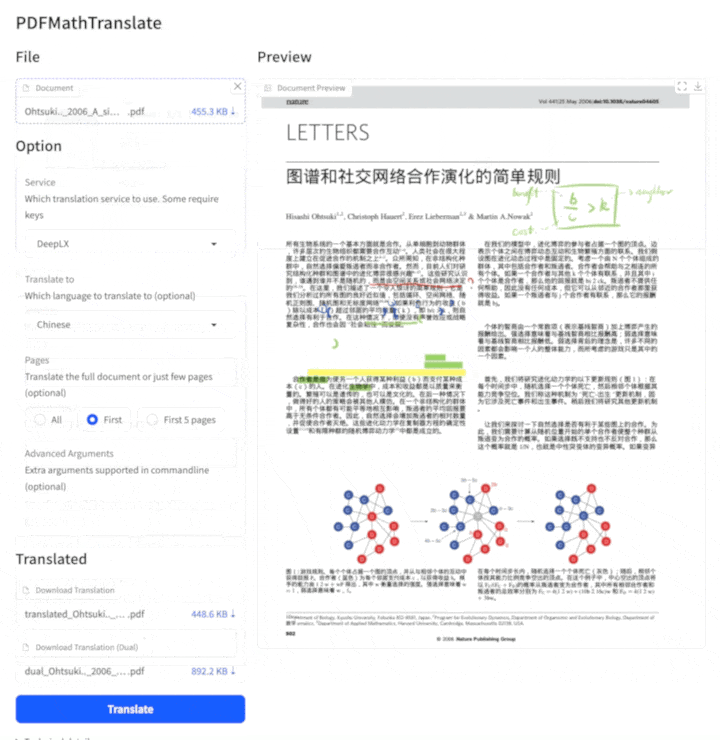
See documentation for GUI for more details.
4. Docker
-
Pull and run:
docker pull byaidu/pdf2zh docker run -d -p 7860:7860 byaidu/pdf2zh -
Open in browser:
http://localhost:7860/
For docker deployment on cloud service:
5. Zotero Plugin
See Zotero PDF2zh for more details.
6. Commandline
-
Python installed (3.10 <= version <= 3.12)
-
Install our package:
pip install pdf2zh -
Execute translation, files generated in current working directory:
pdf2zh document.pdf
[!TIP]
If you're using Windows and cannot open the file after downloading, please install vc_redist.x64.exe and try again.
If you cannot access Docker Hub, please try the image on GitHub Container Registry.
docker pull ghcr.io/byaidu/pdfmathtranslate docker run -d -p 7860:7860 ghcr.io/byaidu/pdfmathtranslate
Unable to install?
The present program needs an AI model(wybxc/DocLayout-YOLO-DocStructBench-onnx) before working and some users are not able to download due to network issues. If you have a problem with downloading this model, we provide a workaround using the following environment variable:
set HF_ENDPOINT=https://hf-mirror.com
For PowerShell user:
$env:HF_ENDPOINT = https://hf-mirror.com
If the solution does not work to you / you encountered other issues, please refer to frequently asked questions.
Advanced Options
Execute the translation command in the command line to generate the translated document example-mono.pdf and the bilingual document example-dual.pdf in the current working directory. Use Google as the default translation service. More support translation services can find HERE.

In the following table, we list all advanced options for reference:
| Option | Function | Example |
|---|---|---|
| files | Local files | pdf2zh ~/local.pdf |
| links | Online files | pdf2zh http://arxiv.org/paper.pdf |
-i |
Enter GUI | pdf2zh -i |
-p |
Partial document translation | pdf2zh example.pdf -p 1 |
-li |
Source language | pdf2zh example.pdf -li en |
-lo |
Target language | pdf2zh example.pdf -lo zh |
-s |
Translation service | pdf2zh example.pdf -s deepl |
-t |
Multi-threads | pdf2zh example.pdf -t 1 |
-o |
Output dir | pdf2zh example.pdf -o output |
-f, -c |
Exceptions | pdf2zh example.pdf -f "(MS.*)" |
-cp |
Compatibility Mode | pdf2zh example.pdf --compatible |
--skip-subset-fonts |
Skip font subset | pdf2zh example.pdf --skip-subset-fonts |
--ignore-cache |
Ignore translate cache | pdf2zh example.pdf --ignore-cache |
--share |
Public link | pdf2zh -i --share |
--authorized |
Authorization | pdf2zh -i --authorized users.txt [auth.html] |
--prompt |
Custom Prompt | pdf2zh --prompt [prompt.txt] |
--onnx |
[Use Custom DocLayout-YOLO ONNX model] | pdf2zh --onnx [onnx/model/path] |
--serverport |
[Use Custom WebUI port] | pdf2zh --serverport 7860 |
--dir |
[batch translate] | pdf2zh --dir /path/to/translate/ |
--config |
configuration file | pdf2zh --config /path/to/config/config.json |
--serverport |
[custom gradio server port] | pdf2zh --serverport 7860 |
--babeldoc |
Use Experimental backend BabelDOC to translate | pdf2zh --babeldoc -s openai example.pdf |
--mcp |
Enable MCP STDIO mode | pdf2zh --mcp |
--sse |
Enable MCP SSE mode | pdf2zh --mcp --sse |
For detailed explanations, please refer to our document about Advanced Usage for a full list of each option.
Secondary Development (APIs)
For downstream applications, please refer to our document about API Details for futher information about:
- Python API, how to use the program in other Python programs
- HTTP API, how to communicate with a server with the program installed
TODOs
-
Parse layout with DocLayNet based models, PaddleX, PaperMage, SAM2
-
Fix page rotation, table of contents, format of lists
-
Fix pixel formula in old papers
-
Async retry except KeyboardInterrupt
-
Knuth–Plass algorithm for western languages
-
Support non-PDF/A files
Acknowledgements
-
Immersive Translation sponsors monthly Pro membership redemption codes for active contributors to this project, see details at: CONTRIBUTOR_REWARD.md
-
New backend: BabelDOC
-
Document merging: PyMuPDF
-
Document parsing: Pdfminer.six
-
Document extraction: MinerU
-
Document Preview: Gradio PDF
-
Multi-threaded translation: MathTranslate
-
Layout parsing: DocLayout-YOLO
-
Document standard: PDF Explained, PDF Cheat Sheets
-
Multilingual Font: Go Noto Universal
Contributors


Star History
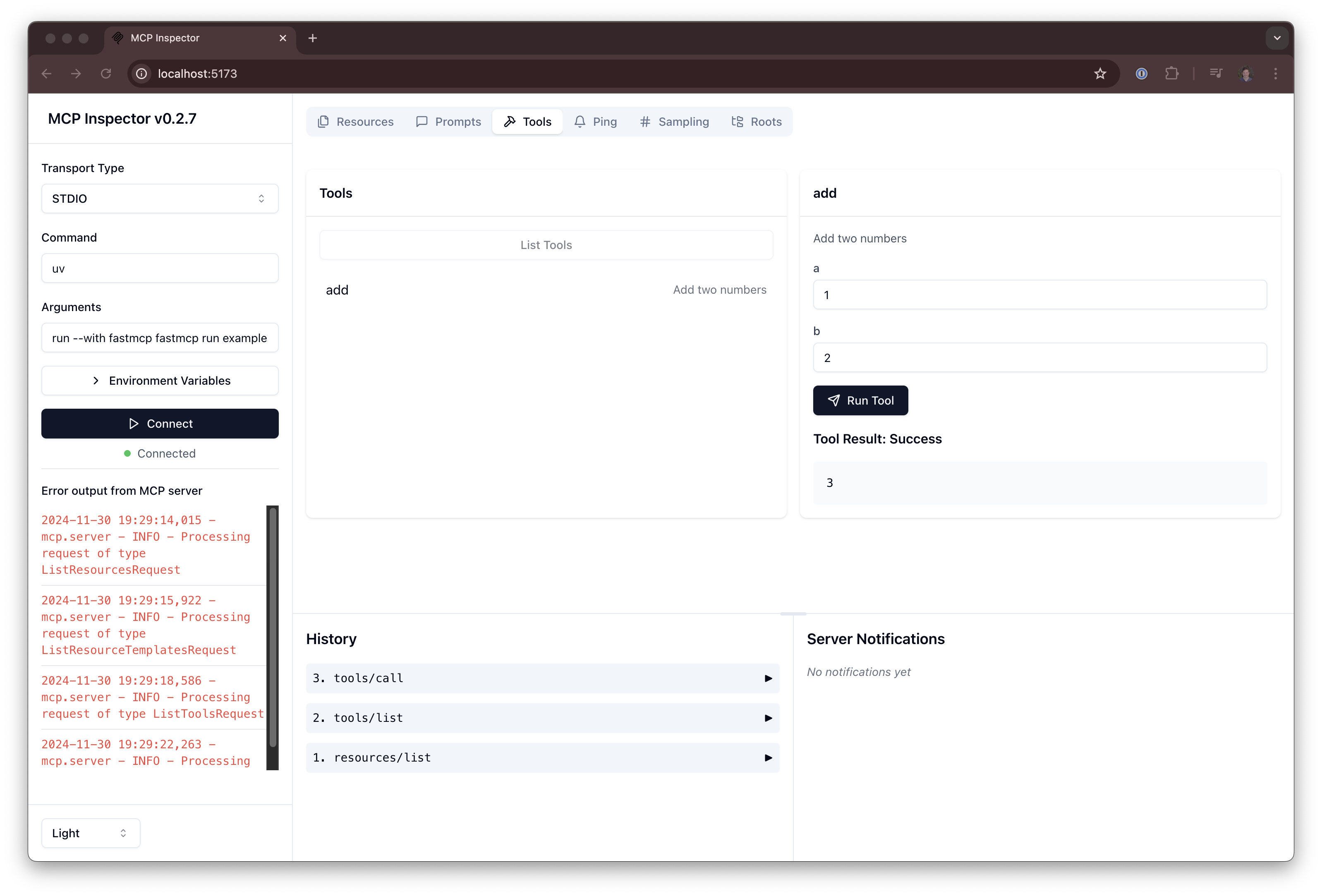
🚀 The fast, Pythonic way to build MCP servers and clients
FastMCP v2 🚀
The fast, Pythonic way to build MCP servers and clients.

![]()

The Model Context Protocol (MCP) is a new, standardized way to provide context and tools to your LLMs, and FastMCP makes building MCP servers and clients simple and intuitive. Create tools, expose resources, define prompts, and connect components with clean, Pythonic code.
# server.py
from fastmcp import FastMCP
mcp = FastMCP("Demo 🚀")
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
if __name__ == "__main__":
mcp.run()
Run the server locally:
fastmcp run server.py
FastMCP handles the complex protocol details and server management, letting you focus on building great tools and applications. It's designed to feel natural to Python developers.
Table of Contents
- What is MCP?
- Why FastMCP?
- Key Features
- What's New in v2?
- Documentation
- Core Concepts
- Advanced Features
- Running Your Server
- Examples
- Contributing
What is MCP?
The Model Context Protocol (MCP) lets you build servers that expose data and functionality to LLM applications in a secure, standardized way. Think of it like a web API, but specifically designed for LLM interactions. MCP servers can:
- Expose data through Resources (think GET endpoints; load info into context)
- Provide functionality through Tools (think POST/PUT endpoints; execute actions)
- Define interaction patterns through Prompts (reusable templates)
- And more!
FastMCP provides a high-level, Pythonic interface for building and interacting with these servers.
Why FastMCP?
The MCP protocol is powerful but implementing it involves a lot of boilerplate - server setup, protocol handlers, content types, error management. FastMCP handles all the complex protocol details and server management, so you can focus on building great tools. It's designed to be high-level and Pythonic; in most cases, decorating a function is all you need.
FastMCP aims to be:
🚀 Fast: High-level interface means less code and faster development
🍀 Simple: Build MCP servers with minimal boilerplate
🐍 Pythonic: Feels natural to Python developers
🔍 Complete: FastMCP aims to provide a full implementation of the core MCP specification for both servers and clients
Key Features
Servers
- Create servers with minimal boilerplate using intuitive decorators
- Proxy existing servers to modify configuration or transport
- Compose servers by into complex applications
- Generate servers from OpenAPI specs or FastAPI objects
Clients
- Interact with MCP servers programmatically
- Connect to any MCP server using any transport
- Test your servers without manual intervention
- Innovate with core MCP capabilities like LLM sampling
What's New in v2?
FastMCP 1.0 made it so easy to build MCP servers that it's now part of the official Model Context Protocol Python SDK! For basic use cases, you can use the upstream version by importing mcp.server.fastmcp.FastMCP (or installing fastmcp=1.0).
Based on how the MCP ecosystem is evolving, FastMCP 2.0 builds on that foundation to introduce a variety of new features (and more experimental ideas). It adds advanced features like proxying and composing MCP servers, as well as automatically generating them from OpenAPI specs or FastAPI objects. FastMCP 2.0 also introduces new client-side functionality like LLM sampling.
Documentation
📚 FastMCP's documentation is available at gofastmcp.com.
Installation
We strongly recommend installing FastMCP with uv, as it is required for deploying servers via the CLI:
uv pip install fastmcp
Note: on macOS, uv may need to be installed with Homebrew (brew install uv) in order to make it available to the Claude Desktop app.
For development, install with:
# Clone the repo first
git clone https://github.com/jlowin/fastmcp.git
cd fastmcp
# Install with dev dependencies
uv sync
Quickstart
Let's create a simple MCP server that exposes a calculator tool and some data:
# server.py
from fastmcp import FastMCP
# Create an MCP server
mcp = FastMCP("Demo")
# Add an addition tool
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
# Add a dynamic greeting resource
@mcp.resource("greeting://{name}")
def get_greeting(name: str) -> str:
"""Get a personalized greeting"""
return f"Hello, {name}!"
You can install this server in Claude Desktop and interact with it right away by running:
fastmcp install server.py
Core Concepts
These are the building blocks for creating MCP servers, using the familiar decorator-based approach.
The FastMCP Server
The central object representing your MCP application. It handles connections, protocol details, and routing.
from fastmcp import FastMCP
# Create a named server
mcp = FastMCP("My App")
# Specify dependencies needed when deployed via `fastmcp install`
mcp = FastMCP("My App", dependencies=["pandas", "numpy"])
Tools
Tools allow LLMs to perform actions by executing your Python functions. They are ideal for tasks that involve computation, external API calls, or side effects.
Decorate synchronous or asynchronous functions with @mcp.tool(). FastMCP automatically generates the necessary MCP schema based on type hints and docstrings. Pydantic models can be used for complex inputs.
import httpx
from pydantic import BaseModel
class UserInfo(BaseModel):
user_id: int
notify: bool = False
@mcp.tool()
async def send_notification(user: UserInfo, message: str) -> dict:
"""Sends a notification to a user if requested."""
if user.notify:
# Simulate sending notification
print(f"Notifying user {user.user_id}: {message}")
return {"status": "sent", "user_id": user.user_id}
return {"status": "skipped", "user_id": user.user_id}
@mcp.tool()
def get_stock_price(ticker: str) -> float:
"""Gets the current price for a stock ticker."""
# Replace with actual API call
prices = {"AAPL": 180.50, "GOOG": 140.20}
return prices.get(ticker.upper(), 0.0)
Resources
Resources expose data to LLMs. They should primarily provide information without significant computation or side effects (like GET requests).
Decorate functions with @mcp.resource("your://uri"). Use curly braces {} in the URI to define dynamic resources (templates) where parts of the URI become function parameters.
# Static resource returning simple text
@mcp.resource("config://app-version")
def get_app_version() -> str:
"""Returns the application version."""
return "v2.1.0"
# Dynamic resource template expecting a 'user_id' from the URI
@mcp.resource("db://users/{user_id}/email")
async def get_user_email(user_id: str) -> str:
"""Retrieves the email address for a given user ID."""
# Replace with actual database lookup
emails = {"123": "[email protected]", "456": "[email protected]"}
return emails.get(user_id, "[email protected]")
# Resource returning JSON data
@mcp.resource("data://product-categories")
def get_categories() -> list[str]:
"""Returns a list of available product categories."""
return ["Electronics", "Books", "Home Goods"]
Prompts
Prompts define reusable templates or interaction patterns for the LLM. They help guide the LLM on how to use your server's capabilities effectively.
Decorate functions with @mcp.prompt(). The function should return the desired prompt content, which can be a simple string, a Message object (like UserMessage or AssistantMessage), or a list of these.
from fastmcp.prompts.base import UserMessage, AssistantMessage
@mcp.prompt()
def ask_review(code_snippet: str) -> str:
"""Generates a standard code review request."""
return f"Please review the following code snippet for potential bugs and style issues:\n```python\n{code_snippet}\n```"
@mcp.prompt()
def debug_session_start(error_message: str) -> list[Message]:
"""Initiates a debugging help session."""
return [
UserMessage(f"I encountered an error:\n{error_message}"),
AssistantMessage("Okay, I can help with that. Can you provide the full traceback and tell me what you were trying to do?")
]
Context
Gain access to MCP server capabilities within your tool or resource functions by adding a parameter type-hinted with fastmcp.Context.
from fastmcp import Context, FastMCP
mcp = FastMCP("Context Demo")
@mcp.resource("system://status")
async def get_system_status(ctx: Context) -> dict:
"""Checks system status and logs information."""
await ctx.info("Checking system status...")
# Perform checks
await ctx.report_progress(1, 1) # Report completion
return {"status": "OK", "load": 0.5, "client": ctx.client_id}
@mcp.tool()
async def process_large_file(file_uri: str, ctx: Context) -> str:
"""Processes a large file, reporting progress and reading resources."""
await ctx.info(f"Starting processing for {file_uri}")
# Read the resource using the context
file_content_resource = await ctx.read_resource(file_uri)
file_content = file_content_resource[0].content # Assuming single text content
lines = file_content.splitlines()
total_lines = len(lines)
for i, line in enumerate(lines):
# Process line...
if (i + 1) % 100 == 0: # Report progress every 100 lines
await ctx.report_progress(i + 1, total_lines)
await ctx.info(f"Finished processing {file_uri}")
return f"Processed {total_lines} lines."
The Context object provides:
- Logging:
ctx.debug(),ctx.info(),ctx.warning(),ctx.error() - Progress Reporting:
ctx.report_progress(current, total) - Resource Access:
await ctx.read_resource(uri) - Request Info:
ctx.request_id,ctx.client_id - Sampling (Advanced):
await ctx.sample(...)to ask the connected LLM client for completions.
Images
Easily handle image input and output using the fastmcp.Image helper class.
from fastmcp import FastMCP, Image
from PIL import Image as PILImage
import io
mcp = FastMCP("Image Demo")
@mcp.tool()
def create_thumbnail(image_data: Image) -> Image:
"""Creates a 100x100 thumbnail from the provided image."""
img = PILImage.open(io.BytesIO(image_data.data)) # Assumes image_data received as Image with bytes
img.thumbnail((100, 100))
buffer = io.BytesIO()
img.save(buffer, format="PNG")
# Return a new Image object with the thumbnail data
return Image(data=buffer.getvalue(), format="png")
@mcp.tool()
def load_image_from_disk(path: str) -> Image:
"""Loads an image from the specified path."""
# Handles reading file and detecting format based on extension
return Image(path=path)
FastMCP handles the conversion to/from the base64-encoded format required by the MCP protocol.
MCP Clients
The Client class lets you interact with any MCP server (not just FastMCP ones) from Python code:
from fastmcp import Client
async with Client("path/to/server") as client:
# Call a tool
result = await client.call_tool("weather", {"location": "San Francisco"})
print(result)
# Read a resource
res = await client.read_resource("db://users/123/profile")
print(res)
You can connect to servers using any supported transport protocol (Stdio, SSE, FastMCP, etc.). If you don't specify a transport, the Client class automatically attempts to detect an appropriate one from your connection string or server object.
Client Methods
The Client class exposes several methods for interacting with MCP servers.
async with Client("path/to/server") as client:
# List available tools
tools = await client.list_tools()
# List available resources
resources = await client.list_resources()
# Call a tool with arguments
result = await client.call_tool("generate_report", {"user_id": 123})
# Read a resource
user_data = await client.read_resource("db://users/123/profile")
# Get a prompt
greeting = await client.get_prompt("welcome", {"name": "Alice"})
# Send progress updates
await client.progress("task-123", 50, 100) # 50% complete
# Basic connectivity testing
await client.ping()
These methods correspond directly to MCP protocol operations, making it easy to interact with any MCP-compatible server (not just FastMCP ones).
Transport Options
FastMCP supports various transport protocols for connecting to MCP servers:
from fastmcp import Client
from fastmcp.client.transports import (
SSETransport,
PythonStdioTransport,
FastMCPTransport
)
# Connect to a server over SSE (common for web-based MCP servers)
async with Client(SSETransport("http://localhost:8000/mcp")) as client:
# Use client here...
# Connect to a Python script using stdio (useful for local tools)
async with Client(PythonStdioTransport("path/to/script.py")) as client:
# Use client here...
# Connect directly to a FastMCP server object in the same process
from your_app import mcp_server
async with Client(FastMCPTransport(mcp_server)) as client:
# Use client here...
Common transport options include:
SSETransport: Connect to a server via Server-Sent Events (HTTP)PythonStdioTransport: Run a Python script and communicate via stdioFastMCPTransport: Connect directly to a FastMCP server objectWSTransport: Connect via WebSockets
In addition, if you pass a connection string or FastMCP server object to the Client constructor, it will try to automatically detect the appropriate transport.
LLM Sampling
Sampling is an MCP feature that allows a server to request a completion from the client LLM, enabling sophisticated use cases while maintaining security and privacy on the server.
import marvin # Or any other LLM client
from fastmcp import Client, Context, FastMCP
from fastmcp.client.sampling import RequestContext, SamplingMessage, SamplingParams
# -- SERVER SIDE --
# Create a server that requests LLM completions from the client
mcp = FastMCP("Sampling Example")
@mcp.tool()
async def generate_poem(topic: str, context: Context) -> str:
"""Generate a short poem about the given topic."""
# The server requests a completion from the client LLM
response = await context.sample(
f"Write a short poem about {topic}",
system_prompt="You are a talented poet who writes concise, evocative verses."
)
return response.text
@mcp.tool()
async def summarize_document(document_uri: str, context: Context) -> str:
"""Summarize a document using client-side LLM capabilities."""
# First read the document as a resource
doc_resource = await context.read_resource(document_uri)
doc_content = doc_resource[0].content # Assuming single text content
# Then ask the client LLM to summarize it
response = await context.sample(
f"Summarize the following document:\n\n{doc_content}",
system_prompt="You are an expert summarizer. Create a concise summary."
)
return response.text
# -- CLIENT SIDE --
# Create a client that handles the sampling requests
async def sampling_handler(
messages: list[SamplingMessage],
params: SamplingParams,
ctx: RequestContext,
) -> str:
"""Handle sampling requests from the server using your preferred LLM."""
# Extract the messages and system prompt
prompt = [m.content.text for m in messages if m.content.type == "text"]
system_instruction = params.systemPrompt or "You are a helpful assistant."
# Use your preferred LLM client to generate completions
return await marvin.say_async(
message=prompt,
instructions=system_instruction,
)
# Connect them together
async with Client(mcp, sampling_handler=sampling_handler) as client:
result = await client.call_tool("generate_poem", {"topic": "autumn leaves"})
print(result.content[0].text)
This pattern is powerful because:
- The server can delegate text generation to the client LLM
- The server remains focused on business logic and data handling
- The client maintains control over which LLM is used and how requests are handled
- No sensitive data needs to be sent to external APIs
Roots Access
FastMCP exposes the MCP roots functionality, allowing clients to specify which file system roots they can access. This creates a secure boundary for tools that need to work with files. Note that the server must account for client roots explicitly.
from fastmcp import Client, RootsList
# Specify file roots that the client can access
roots = ["file:///path/to/allowed/directory"]
async with Client(mcp_server, roots=roots) as client:
# Now tools in the MCP server can access files in the specified roots
await client.call_tool("process_file", {"filename": "data.csv"})
Advanced Features
Building on the core concepts, FastMCP v2 introduces powerful features for more complex scenarios:
Proxy Servers
Create a FastMCP server that acts as an intermediary, proxying requests to another MCP endpoint (which could be a server or another client connection).
Use Cases:
- Transport Conversion: Expose a server running on Stdio (like many local tools) over SSE or WebSockets, making it accessible to web clients or Claude Desktop.
- Adding Functionality: Wrap an existing server to add authentication, request logging, or modified tool behavior.
- Aggregating Servers: Combine multiple backend MCP servers behind a single proxy interface (though
mountmight be simpler for this).
import asyncio
from fastmcp import FastMCP, Client
from fastmcp.client.transports import PythonStdioTransport
# Create a client that connects to the original server
proxy_client = Client(
transport=PythonStdioTransport('path/to/original_stdio_server.py'),
)
# Create a proxy server that connects to the client and exposes its capabilities
proxy = FastMCP.from_client(proxy_client, name="Stdio-to-SSE Proxy")
if __name__ == "__main__":
proxy.run(transport='sse')
FastMCP.from_client is a class method that connects to the target, discovers its capabilities, and dynamically builds the proxy server instance.
Composing MCP Servers
Structure larger MCP applications by creating modular FastMCP servers and "mounting" them onto a parent server. This automatically handles prefixing for tool names and resource URIs, preventing conflicts.
from fastmcp import FastMCP
# --- Weather MCP ---
weather_mcp = FastMCP("Weather Service")
@weather_mcp.tool()
def get_forecast(city: str):
return f"Sunny in {city}"
@weather_mcp.resource("data://temp/{city}")
def get_temp(city: str):
return 25.0
# --- News MCP ---
news_mcp = FastMCP("News Service")
@news_mcp.tool()
def fetch_headlines():
return ["Big news!", "Other news"]
@news_mcp.resource("data://latest_story")
def get_story():
return "A story happened."
# --- Composite MCP ---
mcp = FastMCP("Composite")
# Mount sub-apps with prefixes
mcp.mount("weather", weather_mcp) # Tools prefixed "weather/", resources prefixed "weather+"
mcp.mount("news", news_mcp) # Tools prefixed "news/", resources prefixed "news+"
@mcp.tool()
def ping():
return "Composite OK"
if __name__ == "__main__":
mcp.run()
This promotes code organization and reusability for complex MCP systems.
OpenAPI & FastAPI Generation
Leverage your existing web APIs by automatically generating FastMCP servers from them.
By default, the following rules are applied:
GETrequests -> MCP resourcesGETrequests with path parameters -> MCP resource templates- All other HTTP methods -> MCP tools
You can override these rules to customize or even ignore certain endpoints.
From FastAPI:
from fastapi import FastAPI
from fastmcp import FastMCP
# Your existing FastAPI application
fastapi_app = FastAPI(title="My Existing API")
@fastapi_app.get("/status")
def get_status():
return {"status": "running"}
@fastapi_app.post("/items")
def create_item(name: str, price: float):
return {"id": 1, "name": name, "price": price}
# Generate an MCP server directly from the FastAPI app
mcp_server = FastMCP.from_fastapi(fastapi_app)
if __name__ == "__main__":
mcp_server.run()
From an OpenAPI Specification:
import httpx
import json
from fastmcp import FastMCP
# Load the OpenAPI spec (dict)
# with open("my_api_spec.json", "r") as f:
# openapi_spec = json.load(f)
openapi_spec = { ... } # Your spec dict
# Create an HTTP client to make requests to the actual API endpoint
http_client = httpx.AsyncClient(base_url="https://api.yourservice.com")
# Generate the MCP server
mcp_server = FastMCP.from_openapi(openapi_spec, client=http_client)
if __name__ == "__main__":
mcp_server.run()
Handling stderr
The MCP spec allows for the server to write anything it wants to stderr, and it doesn't specify the format in any way. FastMCP will forward the server's stderr to the client's stderr.
Running Your Server
Choose the method that best suits your needs:
Development Mode (Recommended for Building & Testing)
Use fastmcp dev for an interactive testing environment with the MCP Inspector.
fastmcp dev your_server_file.py
# With temporary dependencies
fastmcp dev your_server_file.py --with pandas --with numpy
# With local package in editable mode
fastmcp dev your_server_file.py --with-editable .
Claude Desktop Integration (For Regular Use)
Use fastmcp install to set up your server for persistent use within the Claude Desktop app. It handles creating an isolated environment using uv.
fastmcp install your_server_file.py
# With a custom name in Claude
fastmcp install your_server_file.py --name "My Analysis Tool"
# With extra packages and environment variables
fastmcp install server.py --with requests -v API_KEY=123 -f .env
Direct Execution (For Advanced Use Cases)
Run your server script directly for custom deployments or integrations outside of Claude. You manage the environment and dependencies yourself.
Add to your your_server_file.py:
if __name__ == "__main__":
mcp.run() # Assuming 'mcp' is your FastMCP instance
Run with:
python your_server_file.py
# or
uv run python your_server_file.py
Server Object Names
If your FastMCP instance is not named mcp, server, or app, specify it using file:object syntax for the dev and install commands:
fastmcp dev my_module.py:my_mcp_instance
fastmcp install api.py:api_app
Examples
Explore the examples/ directory for code samples demonstrating various features:
simple_echo.py: Basic tool, resource, and prompt.complex_inputs.py: Using Pydantic models for tool inputs.mount_example.py: Mounting multiple FastMCP servers.sampling.py: Using LLM completions within your MCP server.screenshot.py: Tool returning an Image object.text_me.py: Tool interacting with an external API.memory.py: More complex example with database interaction.
Contributing
Contributions make the open-source community vibrant! We welcome improvements and features.
Open Developer Guide
Prerequisites
- Python 3.10+
- uv
Setup
- Clone:
git clone https://github.com/jlowin/fastmcp.git && cd fastmcp - Install Env & Dependencies:
uv venv && uv sync(Activate the.venvafter creation)
Testing
Run the test suite:
uv run pytest -vv
Formatting & Linting
We use ruff via pre-commit.
- Install hooks:
pre-commit install - Run checks:
pre-commit run --all-files
Pull Requests
- Fork the repository.
- Create a feature branch.
- Make changes, commit, and push to your fork.
- Open a pull request against the
mainbranch ofjlowin/fastmcp.
Please open an issue or discussion for questions or suggestions!
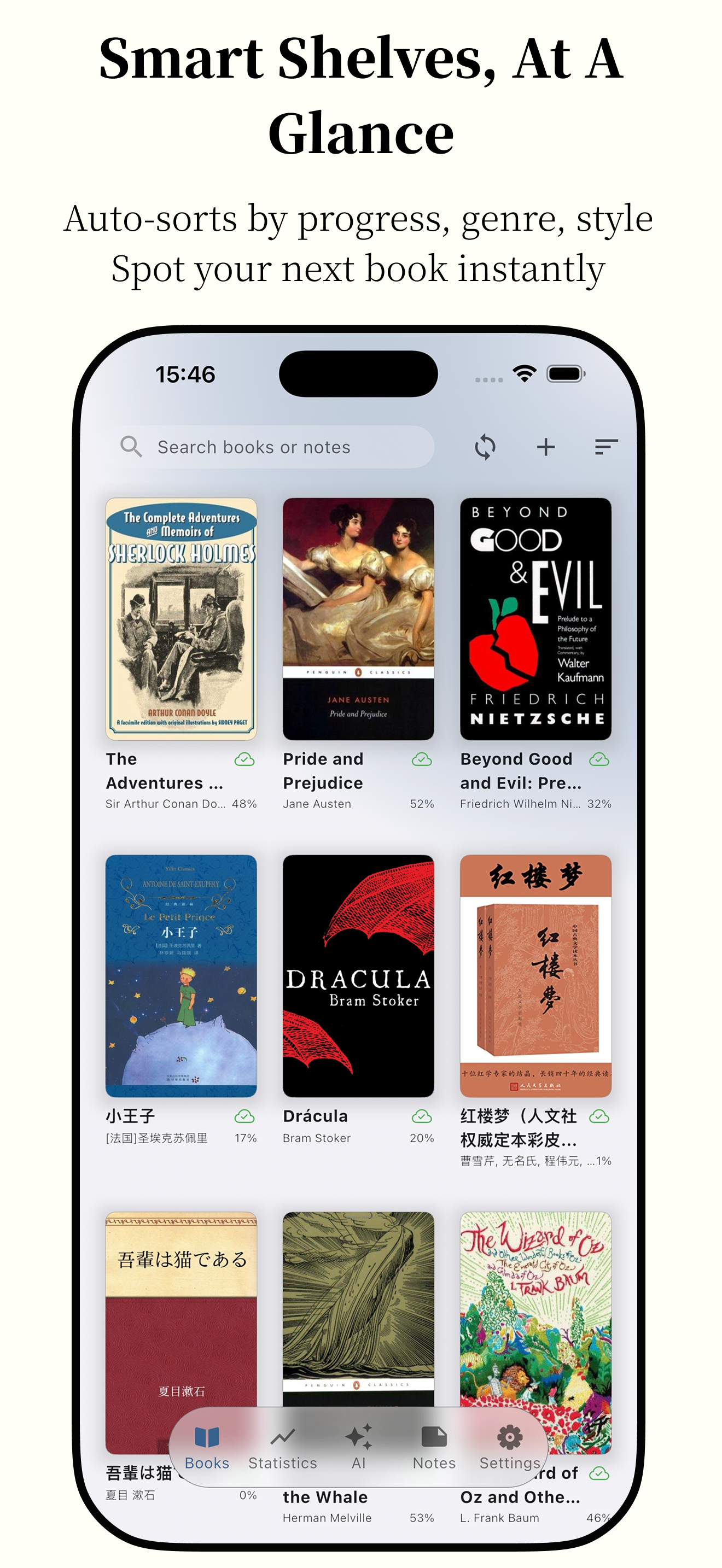
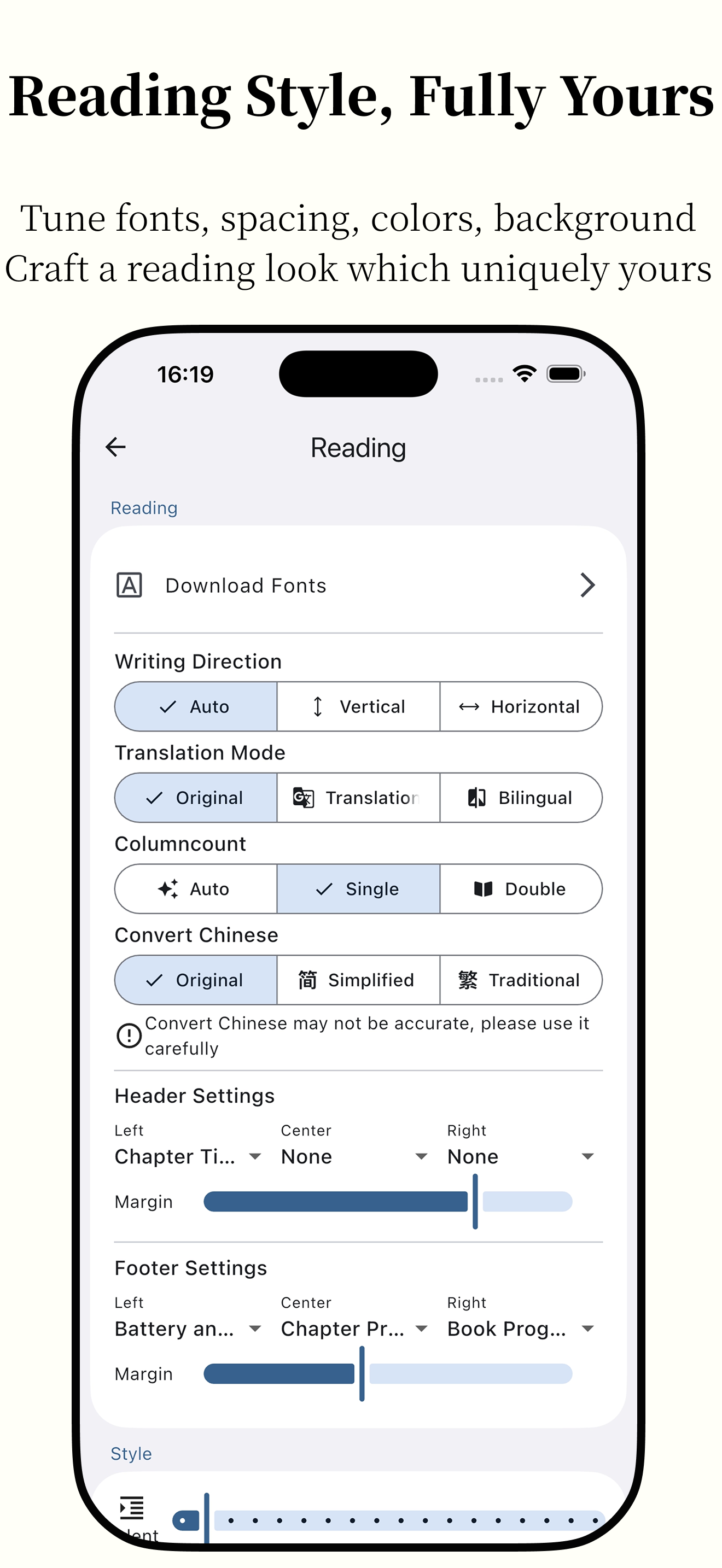
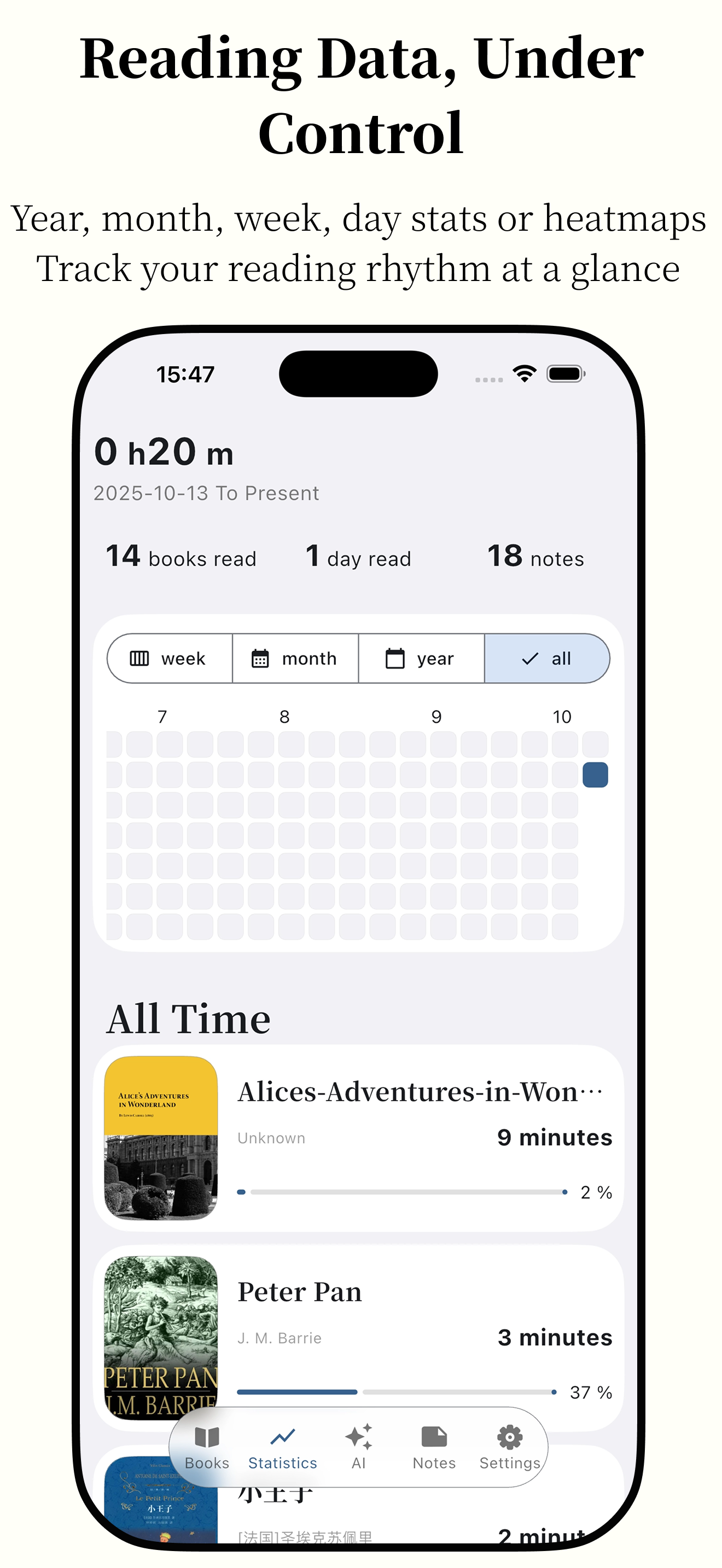
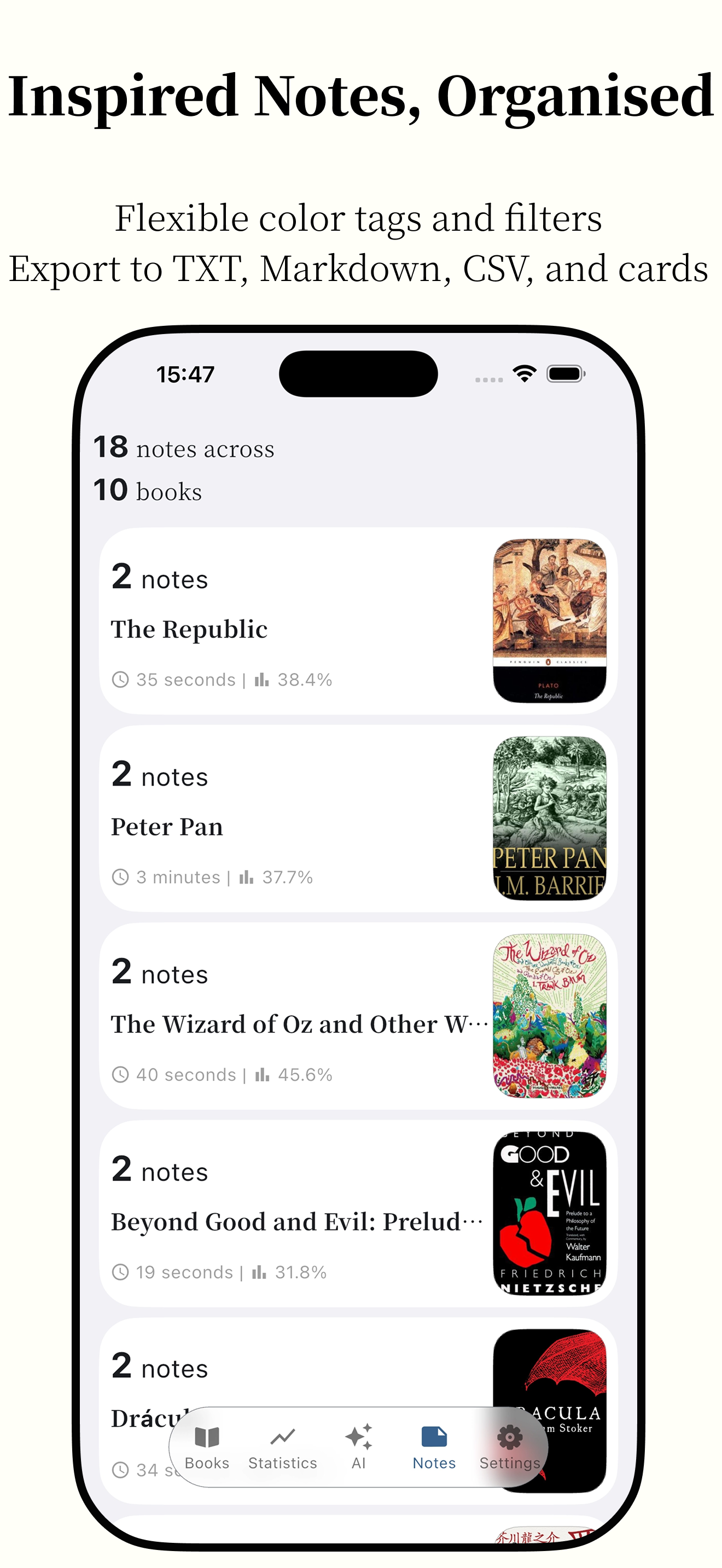
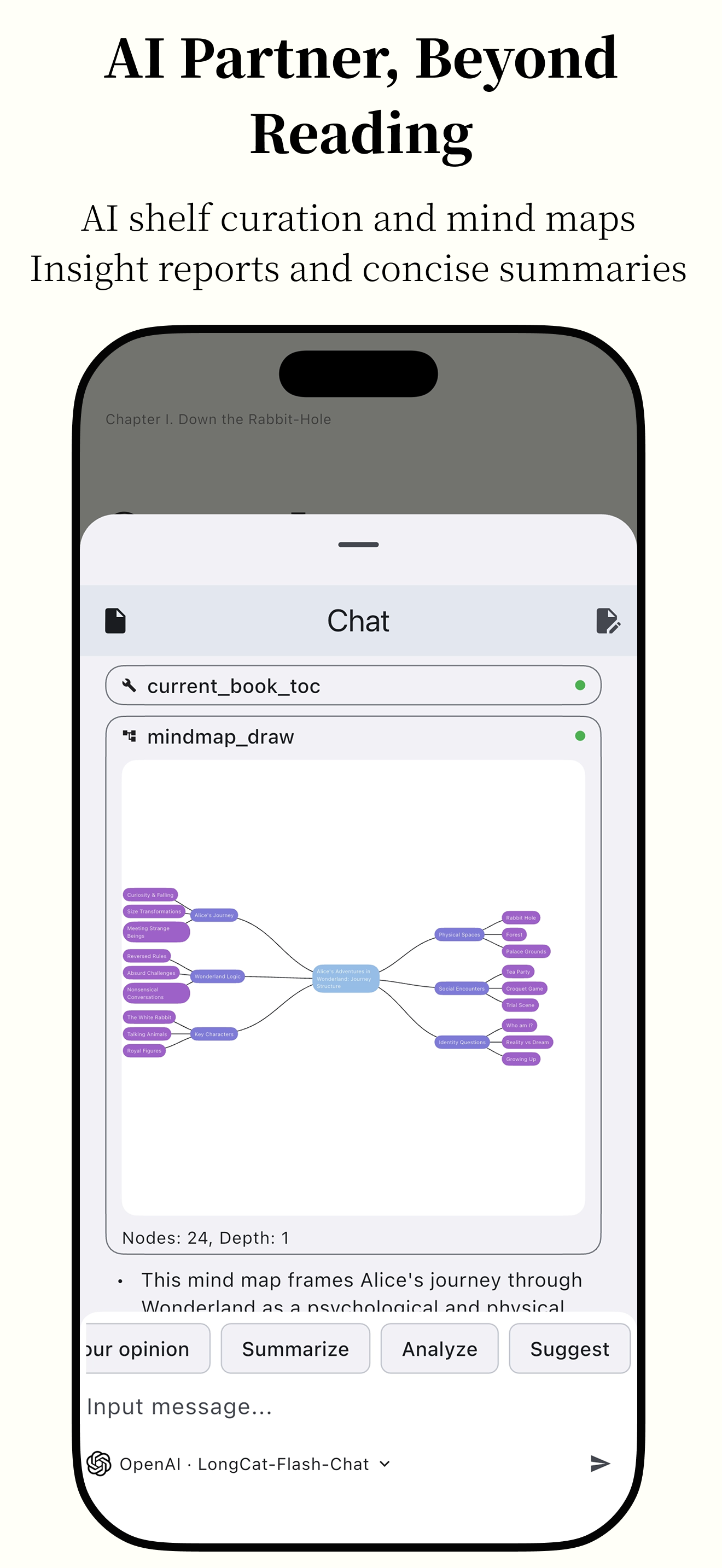
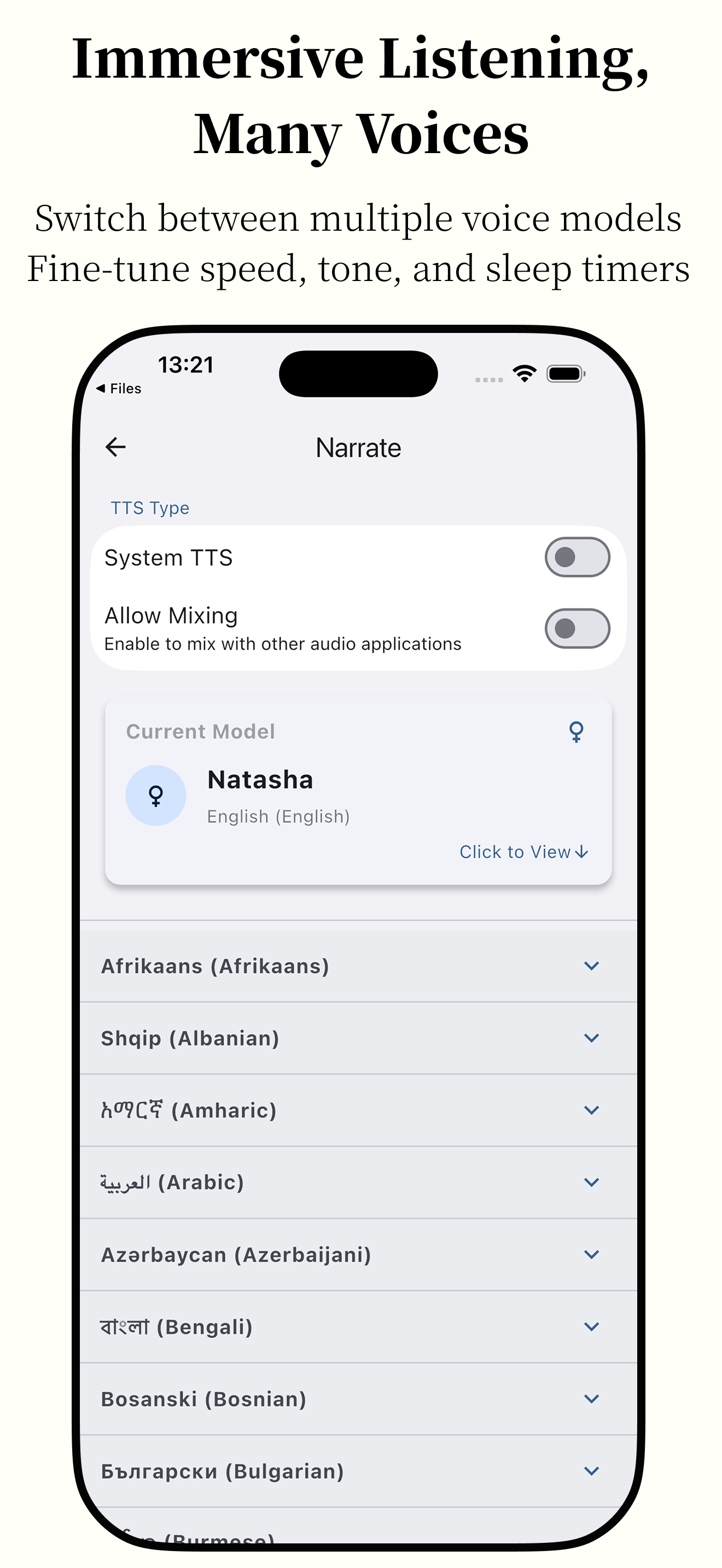
Featuring powerful AI capabilities and supporting various e-book formats, it makes reading smarter and more focused.
![]()
Anx Reader




Anx Reader, a thoughtfully crafted e-book reader for book lovers. Featuring powerful AI capabilities and supporting various e-book formats, it makes reading smarter and more focused. With its modern interface design, we're committed to delivering pure reading pleasure.
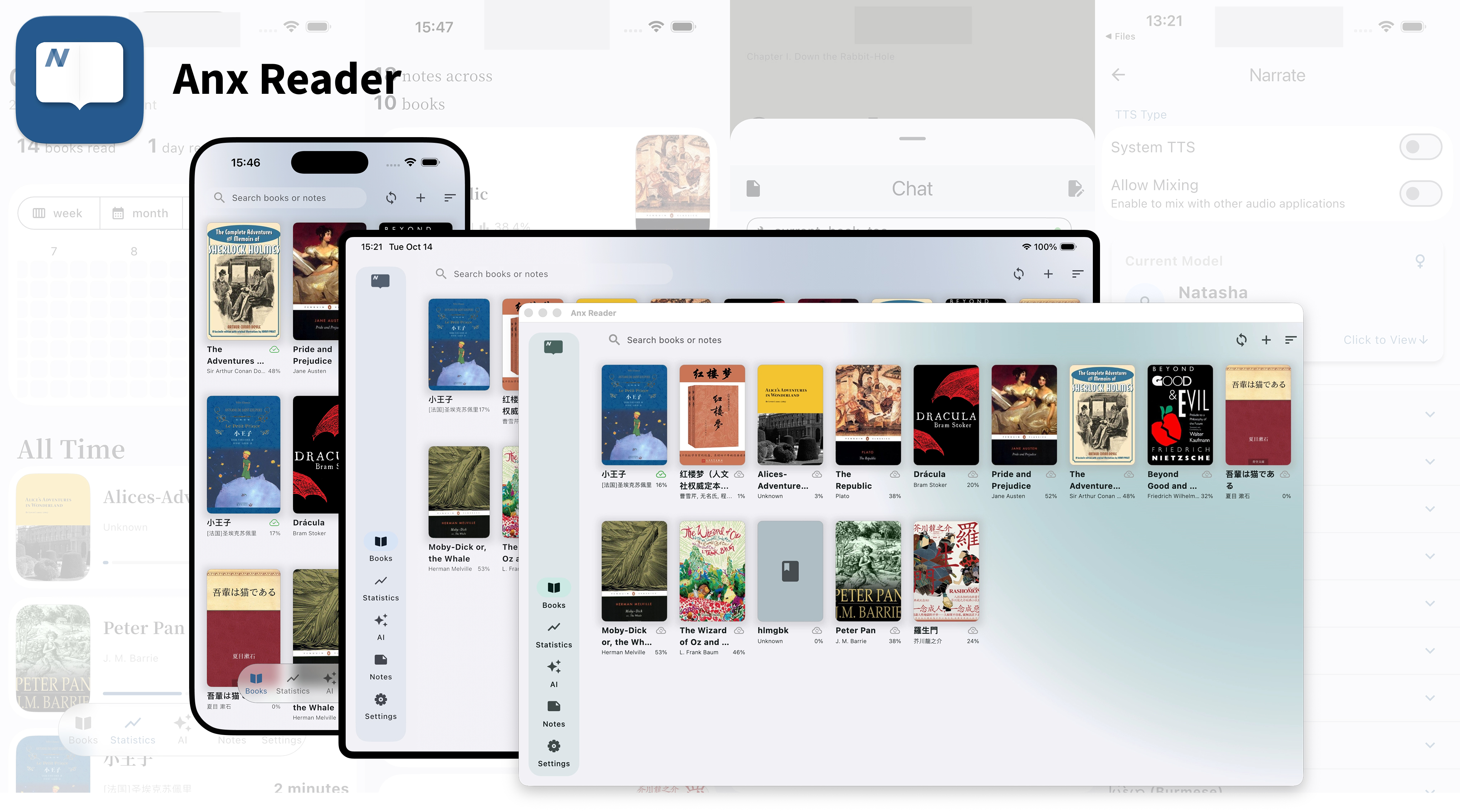
Cross-Platform iOS/macOS/Windows/Android
Full Sync Reading Progress/Book Files/Highlighted Notes
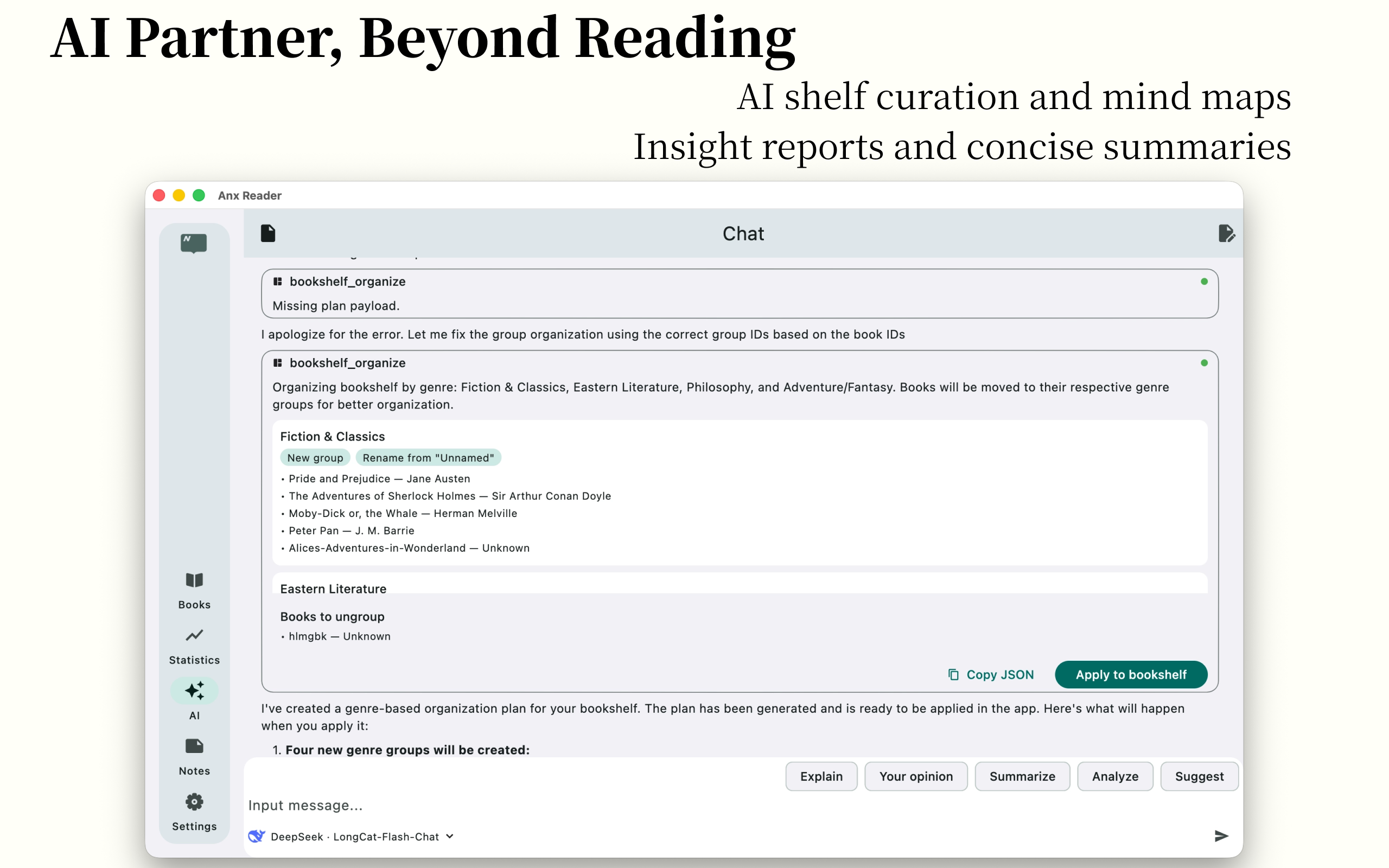
Multiple AI OpenAI/Claude/Gemini/DeepSeek
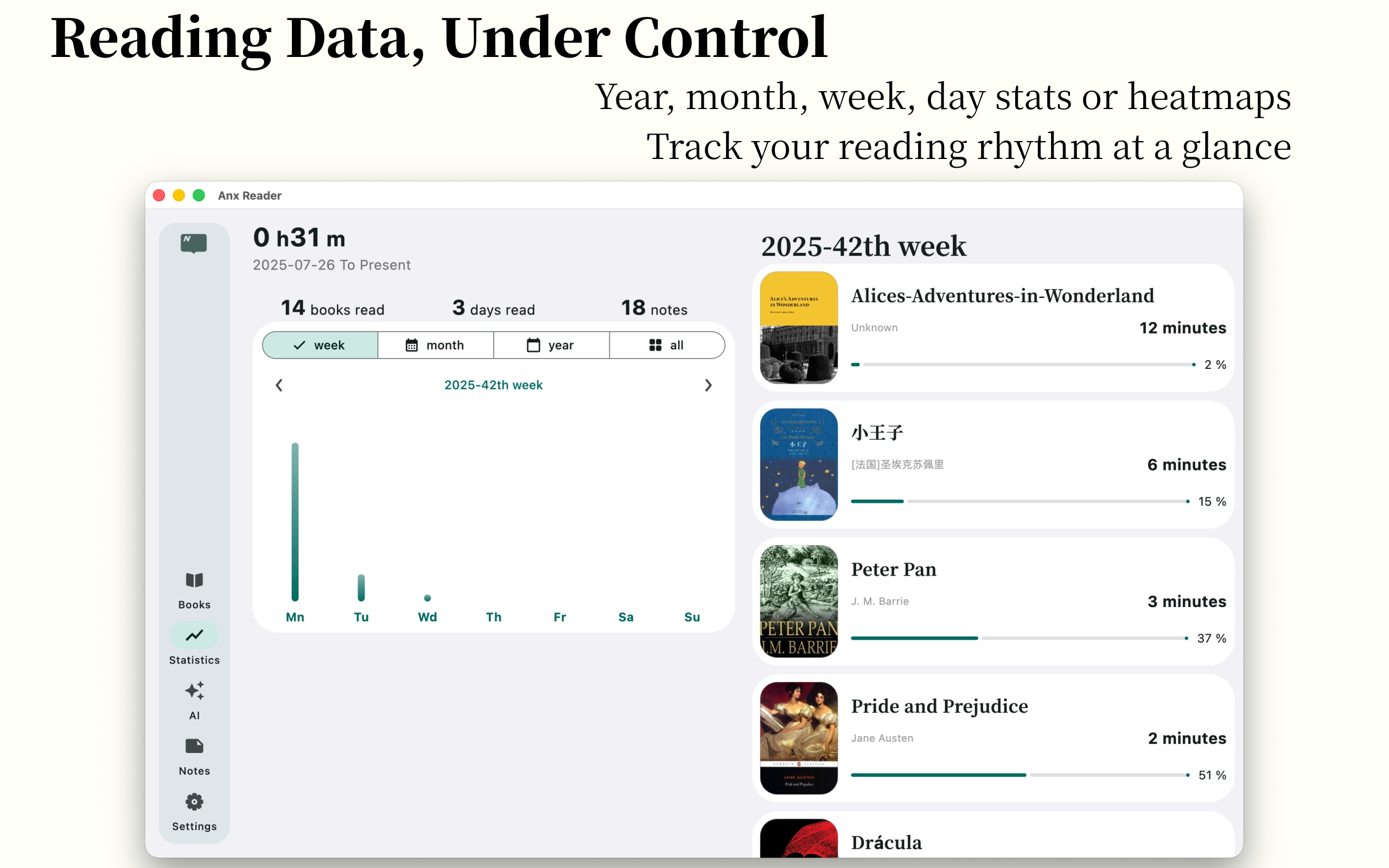
Insightful Data Detailed and Intuitive Charts - Weekly/Monthly/Yearly/Heatmap
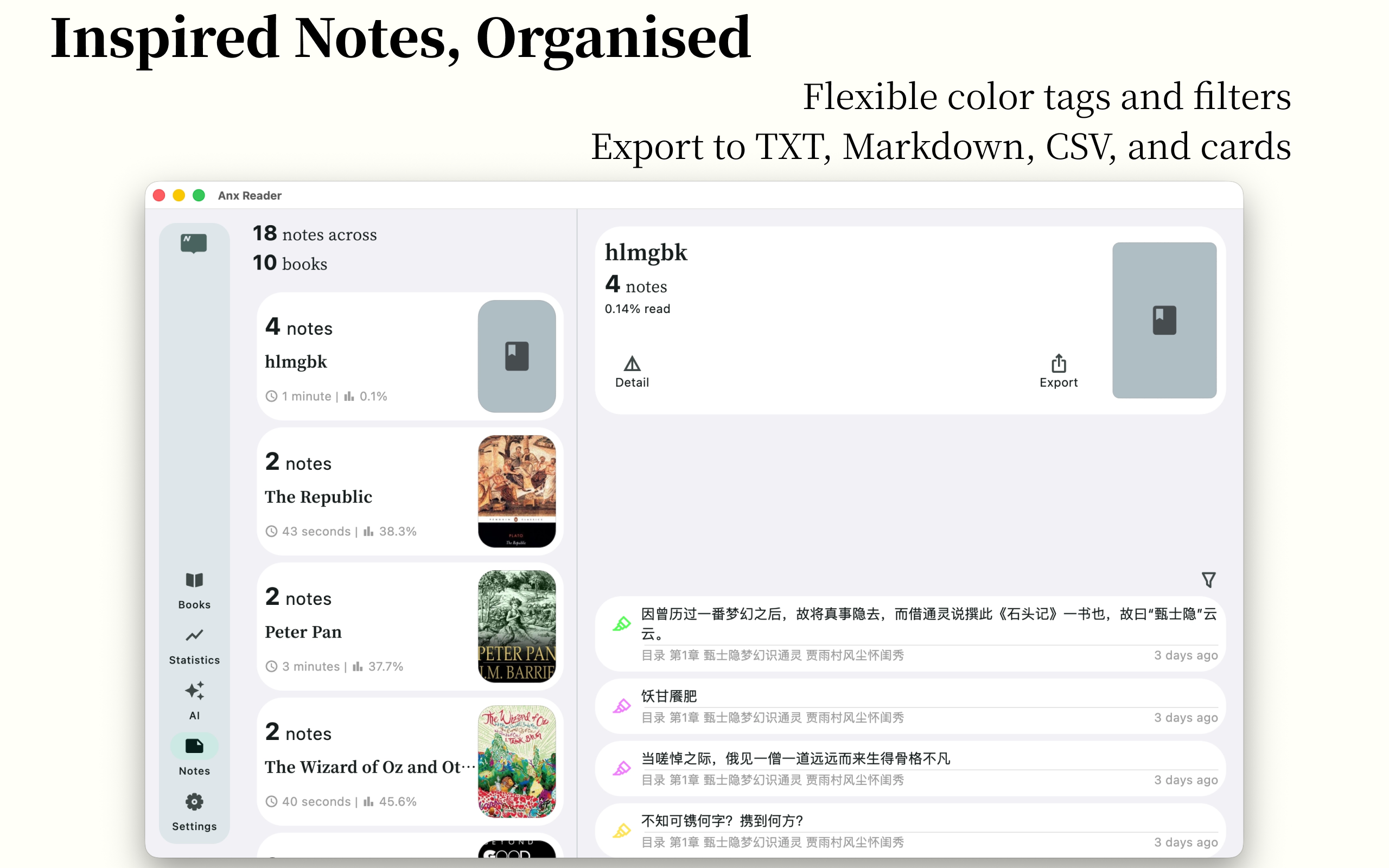
Notes Multiple Ways to Filter/Sort - Export as TXT, Markdown, CSV
Highly Customizable Styles Line Spacing/Paragraph Spacing/Margins/Fonts/Color Schemes/Page Turning Methods
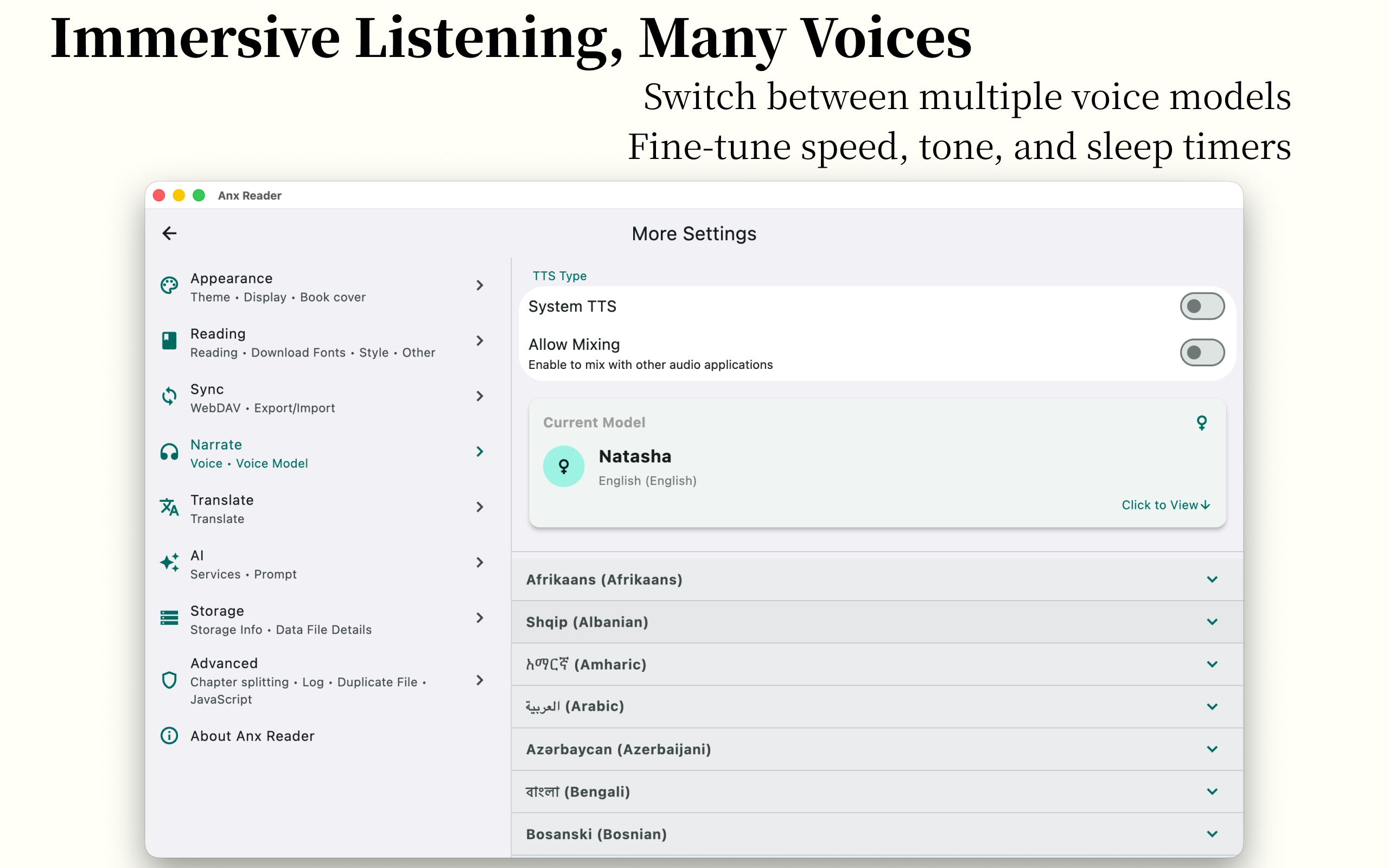
Practical Features Translation/Search/Quick Ask AI/Write Ideas/Text-to-Speech
| OS | Source |
|---|---|
| iOS | |
| macOS | |
| Windows | |
| Android | |
📚 Rich Format Support
- Support for major e-book formats: EPUB, MOBI, AZW3, FB2, TXT
- Perfect parsing for optimal reading experience
☁️ Seamless Sync
- Cross-device synchronization of reading progress, notes, and books via WebDAV
- Continue your reading journey anywhere, anytime
🤖 Smart AI Assistant
- Integration with leading AI services: OpenAI, DeepSeek, Claude, Gemini
- Intelligent content summarization and reading position recall for enhanced efficiency
🎨 Personalized Reading Experience
- Carefully designed theme colors with customization options
- Switch freely between scrolling and pagination modes
- Import custom fonts to create your personal reading space
📊 Professional Reading Analytics
- Comprehensive reading statistics
- Weekly, monthly, and yearly reading reports
- Intuitive reading heatmap to track every moment of your reading journey
📝 Powerful Note System
- Flexible text annotation features
- Export options in TXT, CSV, and Markdown formats
- Easily organize and share your reading insights
🛠️ Practical Tools
- Smart TTS reading to rest your eyes
- Full-text search for quick content location
- Instant word translation to enhance reading efficiency
💻 Cross-Platform Support
- Seamless experience on Android / Windows / MacOS / iOS
- Consistent user interface across devices
TODO
- UI adaptation for tablets
- Page-turning animation
- TTS voice reading
- Reading fonts
- Translation
- Full-text translation
- Support for more file types (pdf)
- Support for WebDAV synchronization
- Support for Linux
I Encountered a Problem, What Should I Do?
Check Troubleshooting
Submit an issue, and we will respond as soon as possible.
Telegram Group: https://t.me/AnxReader
QQ Group:1042905699
Screenshots
 |
 |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
|---|---|---|
 |
 |
 |
Donations
If you like Anx Reader, please consider supporting the project by donating. Your donation will help me maintain and improve the project.
❤️ Donate
Building
Want to build Anx Reader from source? Please follow these steps:
- Install Flutter.
- Clone and enter the project directory.
- Run
flutter pub get. - Run
flutter gen-l10nto generate multi-language files. - Run
dart run build_runner build --delete-conflicting-outputsto generate the Riverpod code. - Run
flutter runto launch the application.
You may encounter Flutter version incompatibility issues. Please refer to the Flutter documentation.
Code signing policy
- Committers and reviewers: Members team
- Approvers: Owners
- Privacy Policy
- Terms of Service
Sponsors
 |
Free code signing on Windows provided by SignPath.io,certficate by SignPath Foundation |
|---|
License
This project is licensed under the MIT License.
Starting from version 1.1.4, the open source license for the Anx Reader project has been changed from the MIT License to the GNU General Public License version 3 (GPLv3).
After version 1.2.6, the selection and highlight feature has been rewritten, and the open source license has been changed from the GPL-3.0 License to the MIT License. All contributors agree to this change(#116).
Thanks
foliate-js, which is MIT licensed, it used as the ebook renderer. Thanks to the author for providing such a great project.
foliate, which is GPL-3.0 licensed, selection and highlight feature is inspired by this project. But since 1.2.6, the selection and highlight feature has been rewritten.
And many other open source projects, thanks to all the authors for their contributions.
[Support 0.48.x](Reset Cursor AI MachineID & Bypass Higher Token Limit) Cursor Ai ,自动重置机器ID , 免费升级使用Pro功能: You've reached your trial request limit. / Too many free trial accounts used on this machine. Please upgrade to pro. We have this limit in place to prevent abuse. Please let us know if you believe this is a mistake.
➤ Cursor Free VIP
![]()

![]()



Support Latest 0.48.x Version | 支持最新 0.48.x 版本
This tool is for educational purposes, currently the repo does not violate any laws. Please support the original project. This tool will not generate any fake email accounts and OAuth access.
Supports Windows, macOS and Linux.
For optimal performance, run with privileges and always stay up to date.
這是一款用於學習和研究的工具,目前 repo 沒有違反任何法律。請支持原作者。 這款工具不會生成任何假的電子郵件帳戶和 OAuth 訪問。
支持 Windows、macOS 和 Linux。
對於最佳性能,請以管理員身份運行並始終保持最新。

🔄 Change Log | 更新日志
✨ Features | 功能特點
-
Support Windows macOS and Linux systems
支持 Windows、macOS 和 Linux 系統 -
Reset Cursor's configuration
重置 Cursor 的配置 -
Multi-language support (English, 简体中文, 繁體中文, Vietnamese)
多語言支持(英文、简体中文、繁體中文、越南語)
💻 System Support | 系統支持
| Operating System | Architecture | Supported |
|---|---|---|
| Windows | x64, x86 | ✅ |
| macOS | Intel, Apple Silicon | ✅ |
| Linux | x64, x86, ARM64 | ✅ |
👀 How to use | 如何使用
⭐ Auto Run Script | 腳本自動化運行
Linux/macOS
curl -fsSL https://raw.githubusercontent.com/yeongpin/cursor-free-vip/main/scripts/install.sh -o install.sh && chmod +x install.sh && ./install.sh
Archlinux
Install via AUR
yay -S cursor-free-vip-git
Windows
irm https://raw.githubusercontent.com/yeongpin/cursor-free-vip/main/scripts/install.ps1 | iex
⭐ Manual Reset Machine | 手動運行重置機器
Linux/macOS
curl -fsSL https://raw.githubusercontent.com/yeongpin/cursor-free-vip/main/scripts/reset.sh | sudo bash
Windows
irm https://raw.githubusercontent.com/yeongpin/cursor-free-vip/main/scripts/reset.ps1 | iex
If you want to stop the script, please press Ctrl+C
要停止腳本,請按 Ctrl+C
❗ Note | 注意事項
📝 Config | 文件配置 Win / Macos / Linux Path | 路徑 [Documents/.cursor-free-vip/config.ini]
⭐ Config | 文件配置
[Chrome]
# Default Google Chrome Path | 默認Google Chrome 遊覽器路徑
chromepath = C:\Program Files\Google/Chrome/Application/chrome.exe
[Turnstile]
# Handle Turnstile Wait Time | 等待人機驗證時間
handle_turnstile_time = 2
# Handle Turnstile Wait Random Time (must merge 1-3 or 1,3) | 等待人機驗證隨機時間(必須是 1-3 或者 1,3 這樣的組合)
handle_turnstile_random_time = 1-3
[OSPaths]
# Storage Path | 存儲路徑
storage_path = /Users/username/Library/Application Support/Cursor/User/globalStorage/storage.json
# SQLite Path | SQLite路徑
sqlite_path = /Users/username/Library/Application Support/Cursor/User/globalStorage/state.vscdb
# Machine ID Path | 機器ID路徑
machine_id_path = /Users/username/Library/Application Support/Cursor/machineId
# For Linux users: ~/.config/cursor/machineid
[Timing]
# Min Random Time | 最小隨機時間
min_random_time = 0.1
# Max Random Time | 最大隨機時間
max_random_time = 0.8
# Page Load Wait | 頁面加載等待時間
page_load_wait = 0.1-0.8
# Input Wait | 輸入等待時間
input_wait = 0.3-0.8
# Submit Wait | 提交等待時間
submit_wait = 0.5-1.5
# Verification Code Input | 驗證碼輸入等待時間
verification_code_input = 0.1-0.3
# Verification Success Wait | 驗證成功等待時間
verification_success_wait = 2-3
# Verification Retry Wait | 驗證重試等待時間
verification_retry_wait = 2-3
# Email Check Initial Wait | 郵件檢查初始等待時間
email_check_initial_wait = 4-6
# Email Refresh Wait | 郵件刷新等待時間
email_refresh_wait = 2-4
# Settings Page Load Wait | 設置頁面加載等待時間
settings_page_load_wait = 1-2
# Failed Retry Time | 失敗重試時間
failed_retry_time = 0.5-1
# Retry Interval | 重試間隔
retry_interval = 8-12
# Max Timeout | 最大超時時間
max_timeout = 160
[Utils]
# Check Update | 檢查更新
check_update = True
# Show Account Info | 顯示賬號信息
show_account_info = True
[WindowsPaths]
storage_path = C:\Users\yeongpin\AppData\Roaming\Cursor\User\globalStorage\storage.json
sqlite_path = C:\Users\yeongpin\AppData\Roaming\Cursor\User\globalStorage\state.vscdb
machine_id_path = C:\Users\yeongpin\AppData\Roaming\Cursor\machineId
cursor_path = C:\Users\yeongpin\AppData\Local\Programs\Cursor\resources\app
updater_path = C:\Users\yeongpin\AppData\Local\cursor-updater
update_yml_path = C:\Users\yeongpin\AppData\Local\Programs\Cursor\resources\app-update.yml
product_json_path = C:\Users\yeongpin\AppData\Local\Programs\Cursor\resources\app\product.json
[Browser]
default_browser = opera
chrome_path = C:\Program Files\Google\Chrome\Application\chrome.exe
edge_path = C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe
firefox_path = C:\Program Files\Mozilla Firefox\firefox.exe
brave_path = C:\Program Files\BraveSoftware/Brave-Browser/Application/brave.exe
chrome_driver_path = D:\VisualCode\cursor-free-vip-new\drivers\chromedriver.exe
edge_driver_path = D:\VisualCode\cursor-free-vip-new\drivers\msedgedriver.exe
firefox_driver_path = D:\VisualCode\cursor-free-vip-new\drivers\geckodriver.exe
brave_driver_path = D:\VisualCode\cursor-free-vip-new\drivers\chromedriver.exe
opera_path = C:\Users\yeongpin\AppData\Local\Programs\Opera\opera.exe
opera_driver_path = D:\VisualCode\cursor-free-vip-new\drivers\chromedriver.exe
[OAuth]
show_selection_alert = False
timeout = 120
max_attempts = 3
-
Use administrator privileges to run the script
請使用管理員身份運行腳本 -
Confirm that Cursor is closed before running the script
請確保在運行腳本前已經關閉 Cursor -
This tool is only for learning and research purposes
此工具僅供學習和研究使用 -
Please comply with the relevant software usage terms when using this tool
使用本工具時請遵守相關軟件使用條款
🚨 Common Issues | 常見問題
| 如果遇到權限問題,請確保: | 此腳本以管理員身份運行 |
|---|---|
| If you encounter permission issues, please ensure: | This script is run with administrator privileges |
| Error 'User is not authorized' | This means your account was banned for using temporary (disposal) mail. Ensure using a non-temporary mail service |
🤩 Contribution | 貢獻
歡迎提交 Issue 和 Pull Request!
📩 Disclaimer | 免責聲明
本工具僅供學習和研究使用,使用本工具所產生的任何後果由使用者自行承擔。
This tool is only for learning and research purposes, and any consequences arising from the use of this tool are borne by the user.
💰 Buy Me a Coffee | 請我喝杯咖啡
 |
 |
⭐ Star History | 星星數
📝 License | 授權
本項目採用 CC BY-NC-ND 4.0 授權。 Please refer to the LICENSE file for details.
Toolkit for linearizing PDFs for LLM datasets/training
olmOCR


A toolkit for training language models to work with PDF documents in the wild.
Try the online demo: https://olmocr.allenai.org/
What is included:
- A prompting strategy to get really good natural text parsing using ChatGPT 4o - buildsilver.py
- An side-by-side eval toolkit for comparing different pipeline versions - runeval.py
- Basic filtering by language and SEO spam removal - filter.py
- Finetuning code for Qwen2-VL and Molmo-O - train.py
- Processing millions of PDFs through a finetuned model using Sglang - pipeline.py
- Viewing Dolma docs created from PDFs - dolmaviewer.py
Installation
Requirements:
- Recent NVIDIA GPU (tested on RTX 4090, L40S, A100, H100) with at least 20 GB of GPU RAM
- 30GB of free disk space
You will need to install poppler-utils and additional fonts for rendering PDF images.
Install dependencies (Ubuntu/Debian)
sudo apt-get update
sudo apt-get install poppler-utils ttf-mscorefonts-installer msttcorefonts fonts-crosextra-caladea fonts-crosextra-carlito gsfonts lcdf-typetools
Set up a conda environment and install olmocr
conda create -n olmocr python=3.11
conda activate olmocr
git clone https://github.com/allenai/olmocr.git
cd olmocr
# For CPU-only operations, ex. running benchmarks
pip install -e .
# For actually converting the files with your own GPU
pip install -e .[gpu] --find-links https://flashinfer.ai/whl/cu124/torch2.4/flashinfer/
Local Usage Example
For quick testing, try the web demo. To run locally, a GPU is required, as inference is powered by sglang under the hood. Convert a Single PDF:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/horribleocr.pdf
Convert an Image file:
python -m olmocr.pipeline ./localworkspace --pdfs random_page.png
Convert Multiple PDFs:
python -m olmocr.pipeline ./localworkspace --pdfs tests/gnarly_pdfs/*.pdf
Results will be stored as JSON in ./localworkspace.
Viewing Results
Extracted text is stored as Dolma-style JSONL inside of the ./localworkspace/results directory.
cat localworkspace/results/output_*.jsonl
View results side-by-side with the original PDFs (uses dolmaviewer command):
python -m olmocr.viewer.dolmaviewer localworkspace/results/output_*.jsonl
Now open ./dolma_previews/tests_gnarly_pdfs_horribleocr_pdf.html in your favorite browser.
Multi-node / Cluster Usage
If you want to convert millions of PDFs, using multiple nodes running in parallel, then olmOCR supports reading your PDFs from AWS S3, and coordinating work using an AWS S3 output bucket.
For example, you can start this command on your first worker node, and it will set up a simple work queue in your AWS bucket and start converting PDFs.
python -m olmocr.pipeline s3://my_s3_bucket/pdfworkspaces/exampleworkspace --pdfs s3://my_s3_bucket/jakep/gnarly_pdfs/*.pdf
Now on any subsequent nodes, just run this and they will start grabbing items from the same workspace queue.
python -m olmocr.pipeline s3://my_s3_bucket/pdfworkspaces/exampleworkspace
If you are at Ai2 and want to linearize millions of PDFs efficiently using beaker, just add the --beaker flag. This will prepare the workspace on your local machine, and then launch N GPU workers in the cluster to start converting PDFs.
For example:
python -m olmocr.pipeline s3://my_s3_bucket/pdfworkspaces/exampleworkspace --pdfs s3://my_s3_bucket/jakep/gnarly_pdfs/*.pdf --beaker --beaker_gpus 4
Full documentation for the pipeline
python -m olmocr.pipeline --help
usage: pipeline.py [-h] [--pdfs PDFS] [--workspace_profile WORKSPACE_PROFILE] [--pdf_profile PDF_PROFILE] [--pages_per_group PAGES_PER_GROUP]
[--max_page_retries MAX_PAGE_RETRIES] [--max_page_error_rate MAX_PAGE_ERROR_RATE] [--workers WORKERS] [--apply_filter] [--stats] [--model MODEL]
[--model_max_context MODEL_MAX_CONTEXT] [--model_chat_template MODEL_CHAT_TEMPLATE] [--target_longest_image_dim TARGET_LONGEST_IMAGE_DIM]
[--target_anchor_text_len TARGET_ANCHOR_TEXT_LEN] [--beaker] [--beaker_workspace BEAKER_WORKSPACE] [--beaker_cluster BEAKER_CLUSTER]
[--beaker_gpus BEAKER_GPUS] [--beaker_priority BEAKER_PRIORITY]
workspace
Manager for running millions of PDFs through a batch inference pipeline
positional arguments:
workspace The filesystem path where work will be stored, can be a local folder, or an s3 path if coordinating work with many workers, s3://bucket/prefix/
options:
-h, --help show this help message and exit
--pdfs PDFS Path to add pdfs stored in s3 to the workspace, can be a glob path s3://bucket/prefix/*.pdf or path to file containing list of pdf paths
--workspace_profile WORKSPACE_PROFILE
S3 configuration profile for accessing the workspace
--pdf_profile PDF_PROFILE
S3 configuration profile for accessing the raw pdf documents
--pages_per_group PAGES_PER_GROUP
Aiming for this many pdf pages per work item group
--max_page_retries MAX_PAGE_RETRIES
Max number of times we will retry rendering a page
--max_page_error_rate MAX_PAGE_ERROR_RATE
Rate of allowable failed pages in a document, 1/250 by default
--workers WORKERS Number of workers to run at a time
--apply_filter Apply basic filtering to English pdfs which are not forms, and not likely seo spam
--stats Instead of running any job, reports some statistics about the current workspace
--model MODEL List of paths where you can find the model to convert this pdf. You can specify several different paths here, and the script will try to use the
one which is fastest to access
--model_max_context MODEL_MAX_CONTEXT
Maximum context length that the model was fine tuned under
--model_chat_template MODEL_CHAT_TEMPLATE
Chat template to pass to sglang server
--target_longest_image_dim TARGET_LONGEST_IMAGE_DIM
Dimension on longest side to use for rendering the pdf pages
--target_anchor_text_len TARGET_ANCHOR_TEXT_LEN
Maximum amount of anchor text to use (characters)
--beaker Submit this job to beaker instead of running locally
--beaker_workspace BEAKER_WORKSPACE
Beaker workspace to submit to
--beaker_cluster BEAKER_CLUSTER
Beaker clusters you want to run on
--beaker_gpus BEAKER_GPUS
Number of gpu replicas to run
--beaker_priority BEAKER_PRIORITY
Beaker priority level for the job
Team
olmOCR is developed and maintained by the AllenNLP team, backed by the Allen Institute for Artificial Intelligence (AI2). AI2 is a non-profit institute with the mission to contribute to humanity through high-impact AI research and engineering. To learn more about who specifically contributed to this codebase, see our contributors page.
License
olmOCR is licensed under Apache 2.0. A full copy of the license can be found on GitHub.
Citing
@misc{olmocr,
title={{olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models}},
author={Jake Poznanski and Jon Borchardt and Jason Dunkelberger and Regan Huff and Daniel Lin and Aman Rangapur and Christopher Wilhelm and Kyle Lo and Luca Soldaini},
year={2025},
eprint={2502.18443},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.18443},
}
NocoBase is an extensibility-first, open-source no-code/low-code platform for building business applications and enterprise solutions.
https://github.com/user-attachments/assets/a50c100a-4561-4e06-b2d2-d48098659ec0
![]()
What is NocoBase
NocoBase is an extensibility-first, open-source no-code development platform.
Instead of investing years of time and millions of dollars in research and development, deploy NocoBase in a few minutes and you'll have a private, controllable, and extremely scalable no-code development platform!
Homepage:
https://www.nocobase.com/
Online Demo:
https://demo.nocobase.com/new
Documents:
https://docs.nocobase.com/
Forum:
https://forum.nocobase.com/
Tutorials:
https://www.nocobase.com/en/tutorials
Use Cases:
https://www.nocobase.com/en/blog/tags/customer-stories
Release Notes
Our blog is regularly updated with release notes and provides a weekly summary.
Distinctive features
1. Data model-driven
Most form-, table-, or process-driven no-code products create data structures directly in the user interface, such as Airtable, where adding a new column to a table is adding a new field. This has the advantage of simplicity of use, but the disadvantage of limited functionality and flexibility to meet the needs of more complex scenarios.
NocoBase adopts the design idea of separating the data structure from the user interface, allowing you to create any number of blocks (data views) for the data collections, with different type, styles, content, and actions in each block. This balances the simplicity of no-code operation with the flexibility of native development.
2. What you see is what you get
NocoBase enables the development of complex and distinctive business systems, but this does not mean that complex and specialized operations are required. With a single click, configuration options are displayed on the usage interface, and administrators with system configuration privileges can directly configure the user interface in a WYSIWYG manner.

3. Everything is implemented as plugins
NocoBase adopts plugin architecture, all new functions can be realized by developing and installing plugins, and expanding the functions is as easy as installing an APP on your phone.
Installation
NocoBase supports three installation methods:
-
Installing With Docker (👍Recommended)
Suitable for no-code scenarios, no code to write. When upgrading, just download the latest image and reboot.
-
Installing from create-nocobase-app CLI
The business code of the project is completely independent and supports low-code development.
-
Installing from Git source code
If you want to experience the latest unreleased version, or want to participate in the contribution, you need to make changes and debug on the source code, it is recommended to choose this installation method, which requires a high level of development skills, and if the code has been updated, you can git pull the latest code.
Docmost is an open-source collaborative wiki and documentation software. It is an open-source alternative to Confluence and Notion.
Docmost
Open-source collaborative wiki and documentation software.
Website | Documentation | Twitter / X
Getting started
To get started with Docmost, please refer to our documentation or try our cloud version .
Features
- Real-time collaboration
- Diagrams (Draw.io, Excalidraw and Mermaid)
- Spaces
- Permissions management
- Groups
- Comments
- Page history
- Search
- File attachments
- Embeds (Airtable, Loom, Miro and more)
- Translations (10+ languages)
Screenshots
License
Docmost core is licensed under the open-source AGPL 3.0 license.
Enterprise features are available under an enterprise license (Enterprise Edition).
All files in the following directories are licensed under the Docmost Enterprise license defined in packages/ee/License.
- apps/server/src/ee
- apps/client/src/ee
- packages/ee
Contributing
See the development documentation
Thanks
Special thanks to;
Crowdin for providing access to their localization platform.
Algolia for providing full-text search to the docs.
🤖 Chat with your SQL database 📊. Accurate Text-to-SQL Generation via LLMs using RAG 🔄.
| GitHub | PyPI | Documentation | Gurubase |
|---|---|---|---|
 |
Vanna
Vanna is an MIT-licensed open-source Python RAG (Retrieval-Augmented Generation) framework for SQL generation and related functionality.
https://github.com/vanna-ai/vanna/assets/7146154/1901f47a-515d-4982-af50-f12761a3b2ce
How Vanna works
Vanna works in two easy steps - train a RAG "model" on your data, and then ask questions which will return SQL queries that can be set up to automatically run on your database.
- Train a RAG "model" on your data.
- Ask questions.
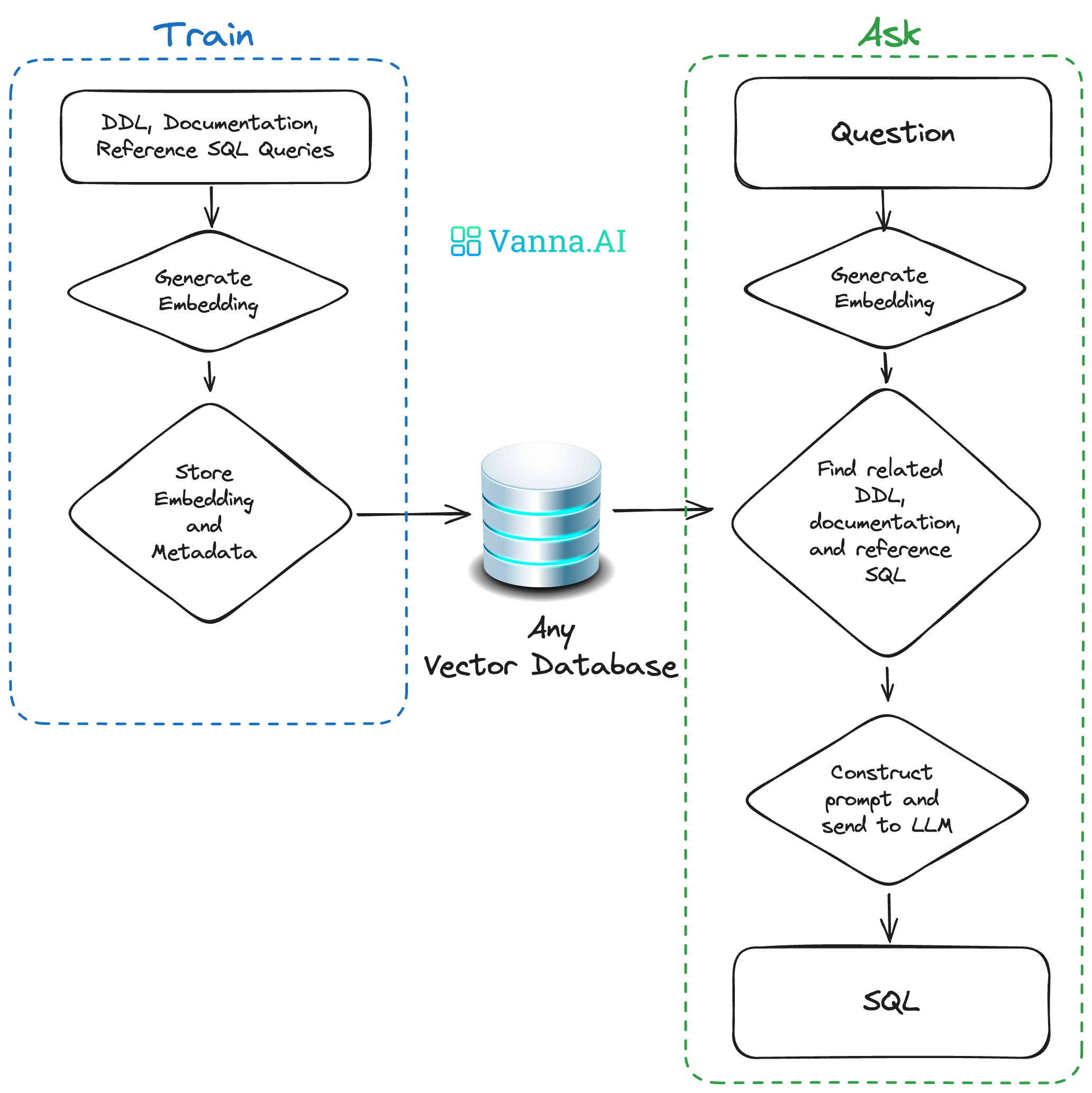
If you don't know what RAG is, don't worry -- you don't need to know how this works under the hood to use it. You just need to know that you "train" a model, which stores some metadata and then use it to "ask" questions.
See the base class for more details on how this works under the hood.
User Interfaces
These are some of the user interfaces that we've built using Vanna. You can use these as-is or as a starting point for your own custom interface.
Supported LLMs
Supported VectorStores
Supported Databases
- PostgreSQL
- MySQL
- PrestoDB
- Apache Hive
- ClickHouse
- Snowflake
- Oracle
- Microsoft SQL Server
- BigQuery
- SQLite
- DuckDB
Getting started
See the documentation for specifics on your desired database, LLM, etc.
If you want to get a feel for how it works after training, you can try this Colab notebook.
Install
pip install vanna
There are a number of optional packages that can be installed so see the documentation for more details.
Import
See the documentation if you're customizing the LLM or vector database.
# The import statement will vary depending on your LLM and vector database. This is an example for OpenAI + ChromaDB
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})
# See the documentation for other options
Training
You may or may not need to run these vn.train commands depending on your use case. See the documentation for more details.
These statements are shown to give you a feel for how it works.
Train with DDL Statements
DDL statements contain information about the table names, columns, data types, and relationships in your database.
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
Train with Documentation
Sometimes you may want to add documentation about your business terminology or definitions.
vn.train(documentation="Our business defines XYZ as ...")
Train with SQL
You can also add SQL queries to your training data. This is useful if you have some queries already laying around. You can just copy and paste those from your editor to begin generating new SQL.
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")
Asking questions
vn.ask("What are the top 10 customers by sales?")
You'll get SQL
SELECT c.c_name as customer_name,
sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o
ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c
ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales desc limit 10;
If you've connected to a database, you'll get the table:
| CUSTOMER_NAME | TOTAL_SALES | |
|---|---|---|
| 0 | Customer#000143500 | 6757566.0218 |
| 1 | Customer#000095257 | 6294115.3340 |
| 2 | Customer#000087115 | 6184649.5176 |
| 3 | Customer#000131113 | 6080943.8305 |
| 4 | Customer#000134380 | 6075141.9635 |
| 5 | Customer#000103834 | 6059770.3232 |
| 6 | Customer#000069682 | 6057779.0348 |
| 7 | Customer#000102022 | 6039653.6335 |
| 8 | Customer#000098587 | 6027021.5855 |
| 9 | Customer#000064660 | 5905659.6159 |
You'll also get an automated Plotly chart: 
RAG vs. Fine-Tuning
RAG
- Portable across LLMs
- Easy to remove training data if any of it becomes obsolete
- Much cheaper to run than fine-tuning
- More future-proof -- if a better LLM comes out, you can just swap it out
Fine-Tuning
- Good if you need to minimize tokens in the prompt
- Slow to get started
- Expensive to train and run (generally)
Why Vanna?
- High accuracy on complex datasets.
- Vanna’s capabilities are tied to the training data you give it
- More training data means better accuracy for large and complex datasets
- Secure and private.
- Your database contents are never sent to the LLM or the vector database
- SQL execution happens in your local environment
- Self learning.
- If using via Jupyter, you can choose to "auto-train" it on the queries that were successfully executed
- If using via other interfaces, you can have the interface prompt the user to provide feedback on the results
- Correct question to SQL pairs are stored for future reference and make the future results more accurate
- Supports any SQL database.
- The package allows you to connect to any SQL database that you can otherwise connect to with Python
- Choose your front end.
- Most people start in a Jupyter Notebook.
- Expose to your end users via Slackbot, web app, Streamlit app, or a custom front end.
Extending Vanna
Vanna is designed to connect to any database, LLM, and vector database. There's a VannaBase abstract base class that defines some basic functionality. The package provides implementations for use with OpenAI and ChromaDB. You can easily extend Vanna to use your own LLM or vector database. See the documentation for more details.
Vanna in 100 Seconds
https://github.com/vanna-ai/vanna/assets/7146154/eb90ee1e-aa05-4740-891a-4fc10e611cab
More resources
AI personal assistant for email. Open source app to help you reach inbox zero fast.
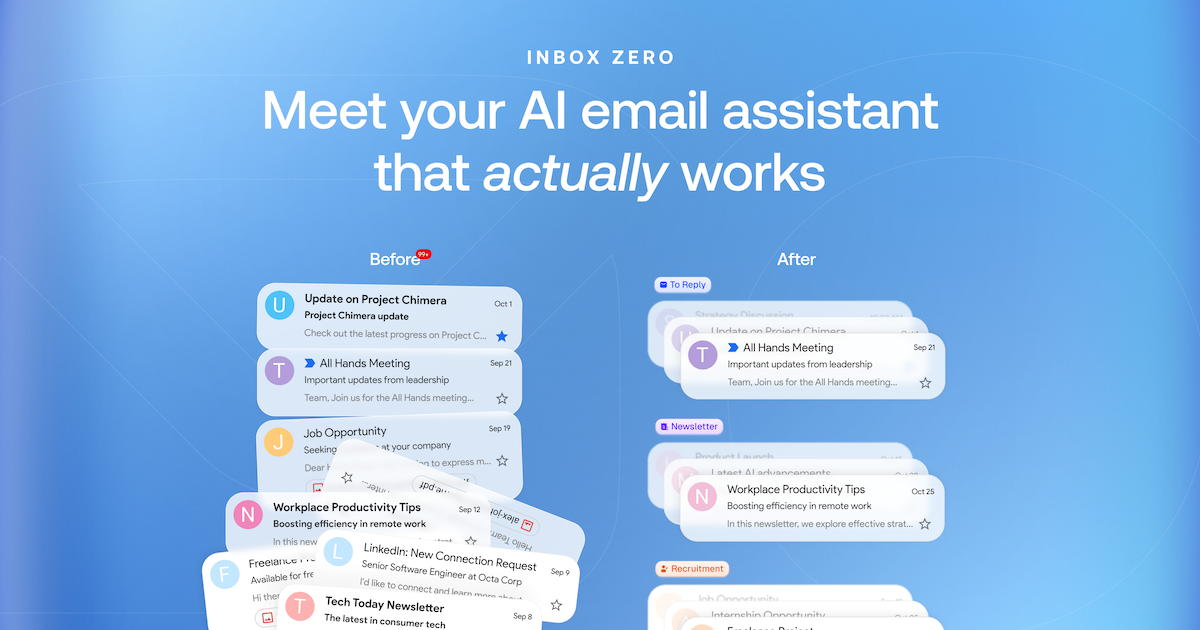
Inbox Zero - Your AI Email Assistant
Open source email app to reach inbox zero fast.
Website · Discord · Issues
About
There are two parts to Inbox Zero:
- An AI email assistant that helps you spend less time on email.
- Open source AI email client.
If you're looking to contribue to the project, the email client is the best place to do this.
Thanks to Vercel for sponsoring Inbox Zero in support of open-source software.
Features
- AI Personal Assistant: Manages your email for you based on a plain text prompt file. It can take any action a human assistant can take on your behalf (Draft reply, Label, Archive, Reply, Forward, Mark Spam, and even call a webhook).
- Reply Zero: Track emails that need your reply and those awaiting responses.
- Smart Categories: Categorize everyone that's ever emailed you.
- Bulk Unsubscriber: Quickly unsubscribe from emails you never read in one-click.
- Cold Email Blocker: Automatically block cold emails.
- Email Analytics: Track your email activity with daily, weekly, and monthly stats.
Learn more in our docs.
Feature Screenshots
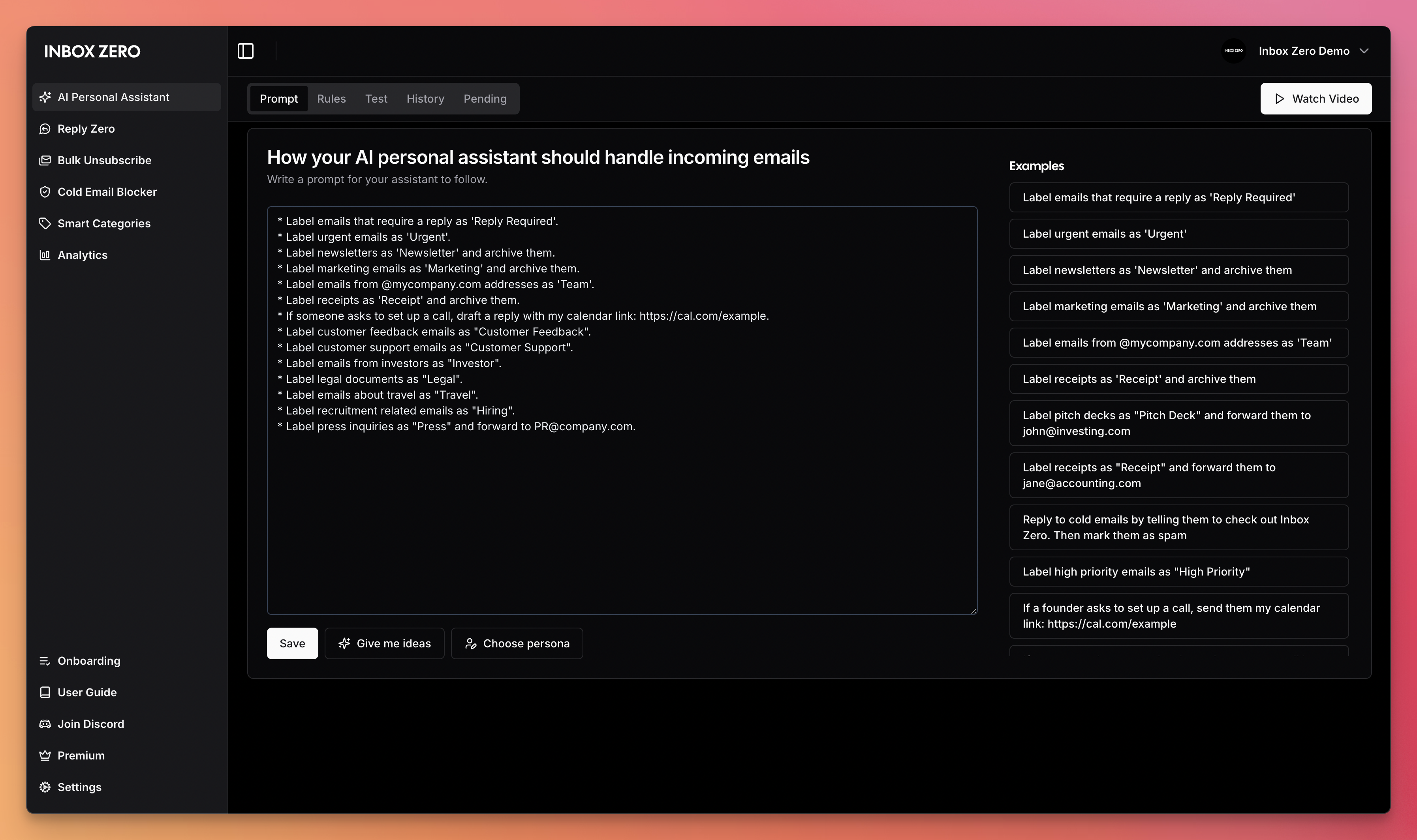 |
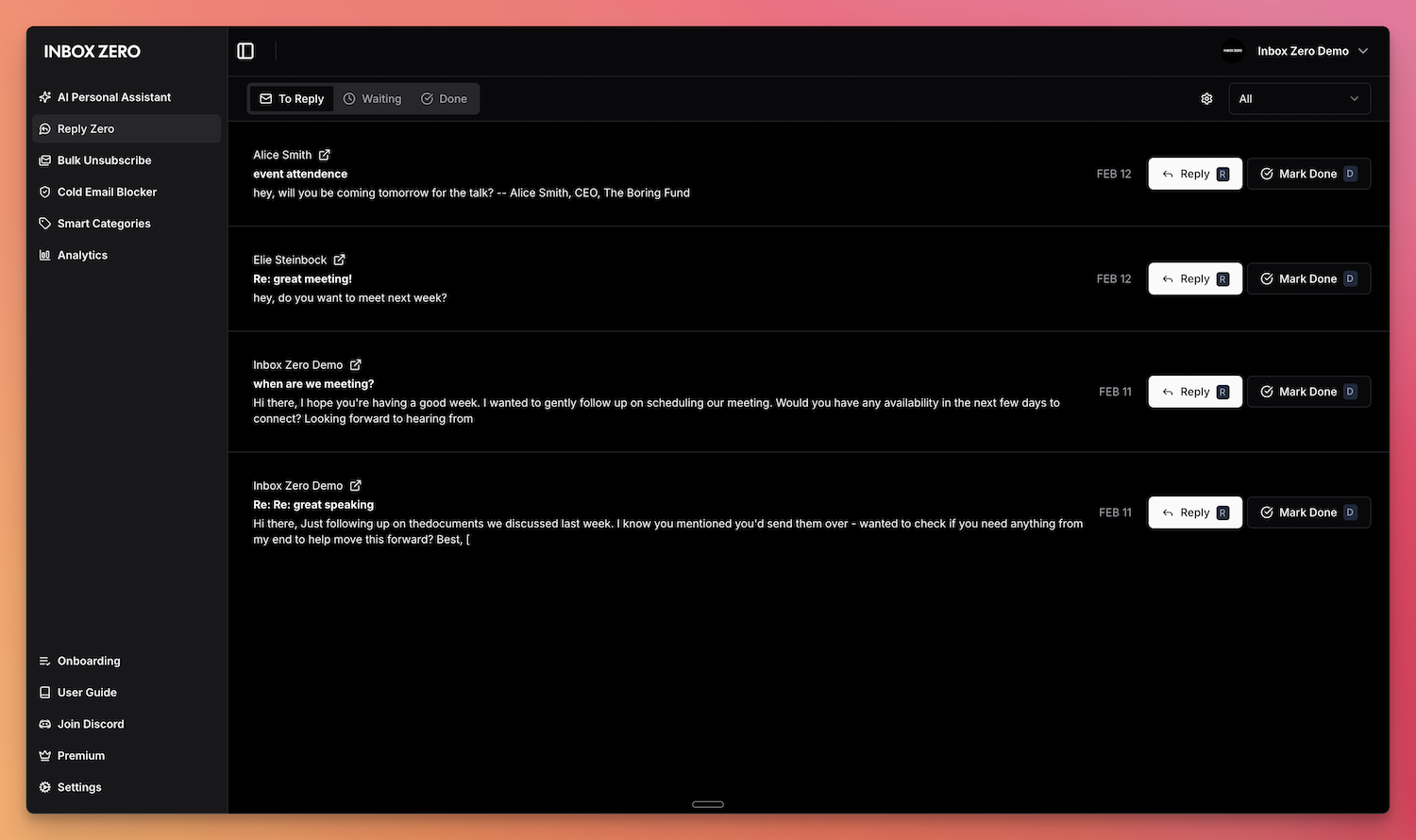 |
|---|---|
| AI Assistant | Reply Zero |
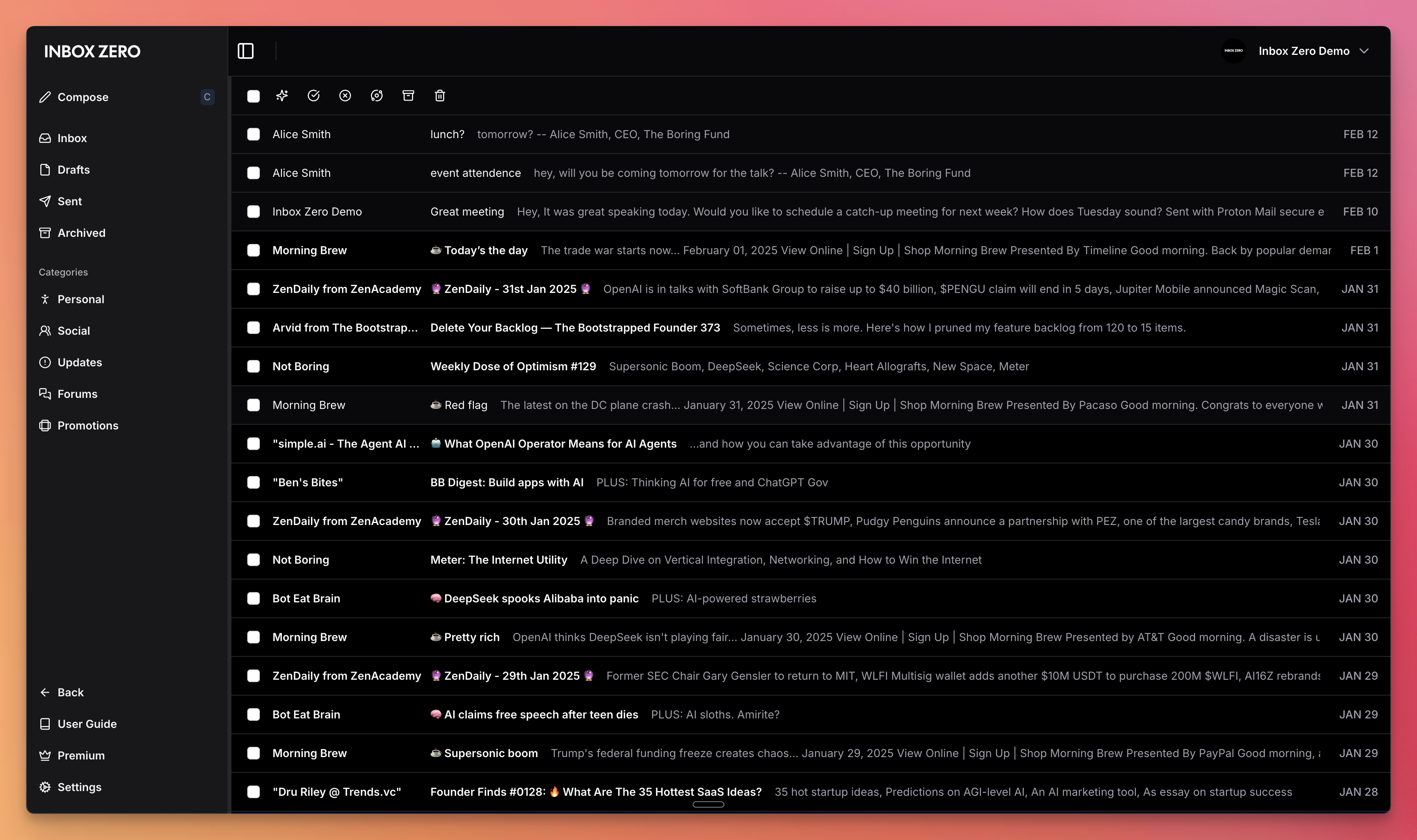 |
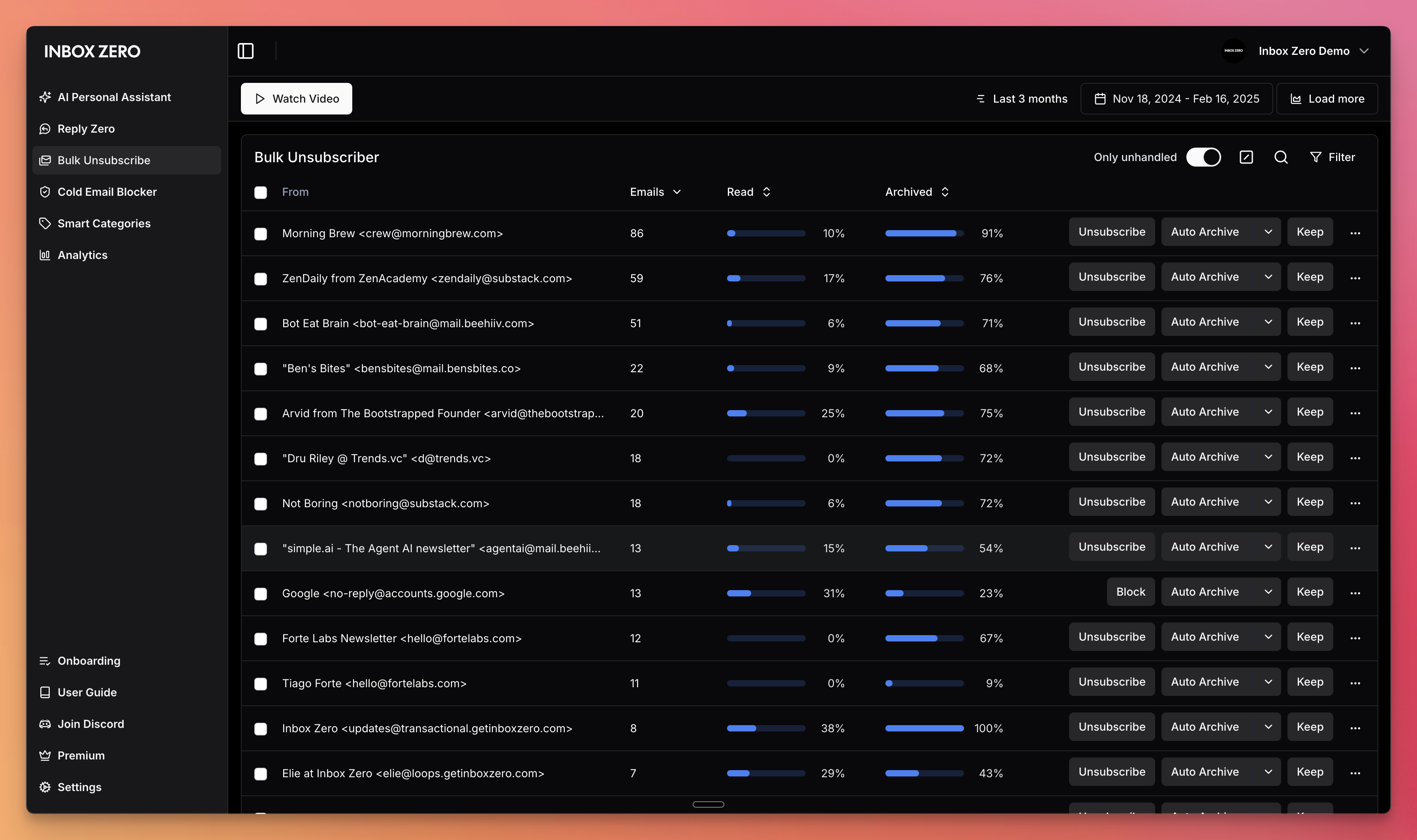 |
| Gmail client | Bulk Unsubscriber |
Demo Video
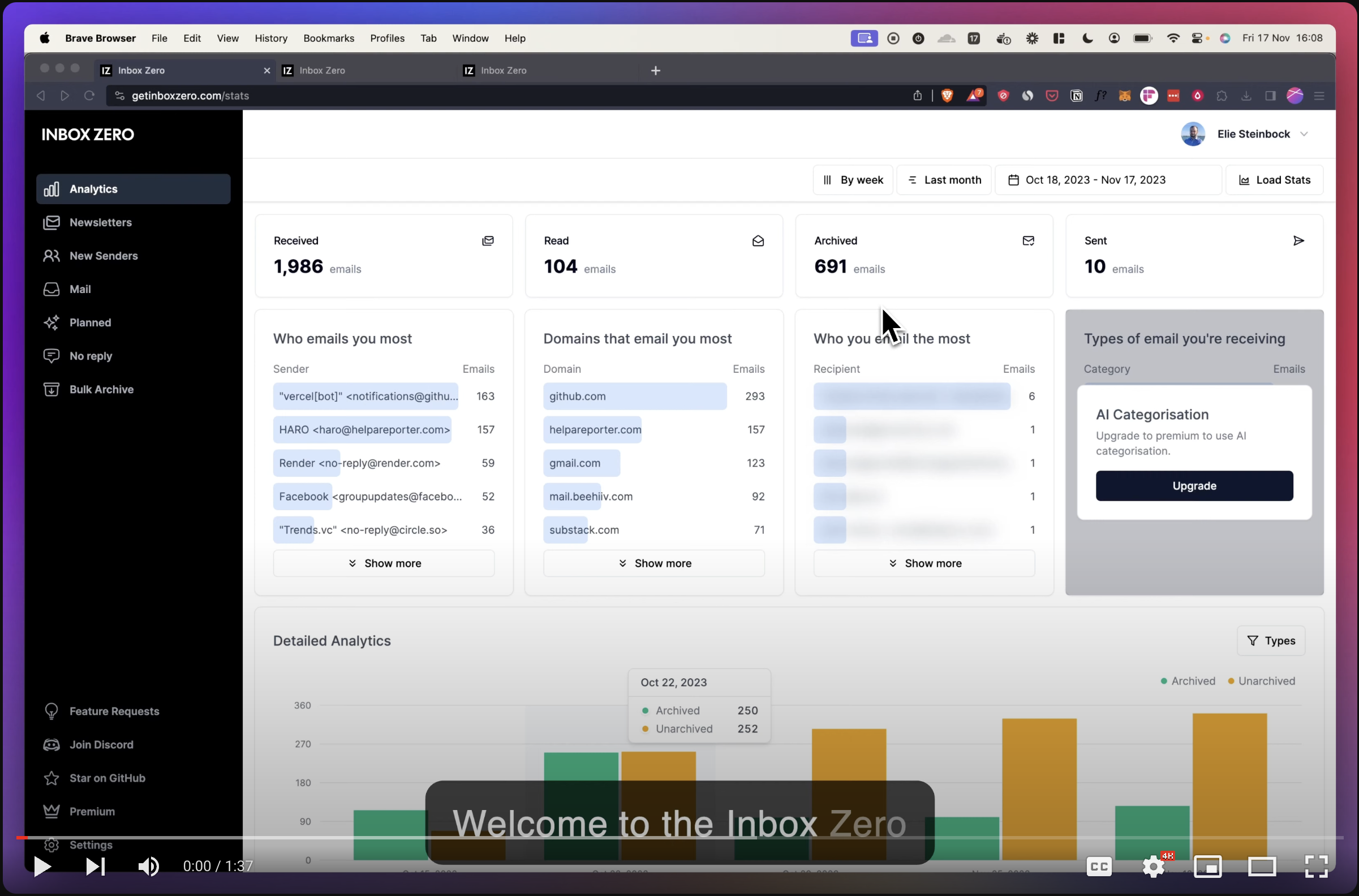
Built with
Star History
Feature Requests
To request a feature open a GitHub issue, or join our Discord.
Getting Started for Developers
We offer a hosted version of Inbox Zero at https://getinboxzero.com. To self-host follow the steps below.
Contributing to the project
You can view open tasks in our GitHub Issues. Join our Discord to discuss tasks and check what's being worked on.
ARCHITECTURE.md explains the architecture of the project (LLM generated).
Requirements
- Node.js >= 18.0.0
- pnpm >= 8.6.12
- Docker desktop (optional)
Setup
Here's a video on how to set up the project. It covers the same steps mentioned in this document. But goes into greater detail on setting up the external services.
The external services that are required are:
- Google OAuth
- Google PubSub - see set up instructions below
You also need to set an LLM, but you can use a local one too:
- Anthropic
- OpenAI
- AWS Bedrock Anthropic
- Google Gemini
- OpenRouter (any model)
- Groq (Llama 3.3 70B)
- Ollama (local)
Create your own .env file:
cp apps/web/.env.example apps/web/.env
cd apps/web
pnpm install
For self-hosting, you may also need to copy the .env file to both the root directory AND the apps/web directory (PRs welcome to improve this):
cp apps/web/.env .env
Set the environment variables in the newly created .env. You can see a list of required variables in: apps/web/env.ts.
The required environment variables:
NEXTAUTH_SECRET-- can be any random string (try usingopenssl rand -hex 32for a quick secure random string)GOOGLE_CLIENT_ID-- Google OAuth client ID. More info hereGOOGLE_CLIENT_SECRET-- Google OAuth client secret. More info hereGOOGLE_ENCRYPT_SECRET-- Secret key for encrypting OAuth tokens (try usingopenssl rand -hex 32for a secure key)GOOGLE_ENCRYPT_SALT-- Salt for encrypting OAuth tokens (try usingopenssl rand -hex 16for a secure salt)UPSTASH_REDIS_URL-- Redis URL from Upstash. (can be empty if you are using Docker Compose)UPSTASH_REDIS_TOKEN-- Redis token from Upstash. (or specify your own random string if you are using Docker Compose)
We use Postgres for the database. For Redis, you can use Upstash Redis or set up your own Redis instance.
You can run Postgres & Redis locally using docker-compose
docker-compose up -d # -d will run the services in the background
When using Vercel with Fluid Compute turned off, you should set MAX_DURATION=300 or lower. See Vercel limits for different plans here.
To run the migrations:
pnpm prisma migrate dev
To run the app locally for development (slower):
pnpm run dev
Or from the project root:
turbo dev
To build and run the app locally in production mode (faster):
pnpm run build
pnpm start
Open http://localhost:3000 to view the app in your browser.
To upgrade yourself, make yourself an admin in the .env: [email protected] Then upgrade yourself at: http://localhost:3000/admin.
Supported LLMs
For the LLM, you can use Anthropic, OpenAI, or Anthropic on AWS Bedrock. You can also use Ollama by setting the following enviroment variables:
DEFAULT_LLM_PROVIDER=ollama
OLLAMA_BASE_URL=http://localhost:11434/api
NEXT_PUBLIC_OLLAMA_MODEL=gemma3 # or whatever available model you want to use
Note: If you need to access Ollama hosted locally and the application is running on Docker setup, you can use http://host.docker.internal:11434/api as the base URL. You might also need to set OLLAMA_HOST to 0.0.0.0 in the Ollama configuration file.
You can select the model you wish to use in the app on the /settings page of the app.
Setting up Google OAuth and Gmail API
-
Create a Project in Google Cloud Console
- Go to Google Cloud Console
- Create a new project
-
Enable Required APIs
- Enable the Gmail API
- Enable the People API
-
Configure the OAuth Consent Screen
- Go to 'APIs & Services' > 'OAuth consent screen'
- Choose 'External' user type (or 'Internal' if you have Google Workspace)
- Fill in required app information
- Add the following scopes:
https://www.googleapis.com/auth/userinfo.profile https://www.googleapis.com/auth/userinfo.email https://www.googleapis.com/auth/gmail.modify https://www.googleapis.com/auth/gmail.settings.basic https://www.googleapis.com/auth/contacts - Add yourself as a test user under 'Test users' section
-
Create OAuth 2.0 Credentials
- Go to 'APIs & Services' > 'Credentials'
- Click 'Create Credentials' > 'OAuth client ID'
- Select 'Web application' type
- Add authorized JavaScript origins:
- Development:
http://localhost:3000 - Production:
https://your-production-url.com
- Development:
- Add authorized redirect URIs:
- Development:
http://localhost:3000/api/auth/callback/google - Production:
https://your-production-url.com/api/auth/callback/google
- Development:
-
Configure Environment Variables
- Add to your
.envfile:GOOGLE_CLIENT_ID=your_client_id GOOGLE_CLIENT_SECRET=your_client_secret
- Add to your
Set up push notifications via Google PubSub to handle emails in real time
Follow instructions here.
Set env var GOOGLE_PUBSUB_TOPIC_NAME. When creating the subscription select Push and the url should look something like: https://www.getinboxzero.com/api/google/webhook?token=TOKEN or https://abc.ngrok-free.app/api/google/webhook?token=TOKEN where the domain is your domain. Set GOOGLE_PUBSUB_VERIFICATION_TOKEN in your .env file to be the value of TOKEN.
To run in development ngrok can be helpful:
ngrok http 3000
# or with an ngrok domain to keep your endpoint stable (set `XYZ`):
ngrok http --domain=XYZ.ngrok-free.app 3000
And then update the webhook endpoint in the Google PubSub subscriptions dashboard.
To start watching emails visit: /api/google/watch/all
Watching for email updates
Set a cron job to run these: The Google watch is necessary. Others are optional.
"crons": [
{
"path": "/api/google/watch/all",
"schedule": "0 1 * * *"
},
{
"path": "/api/resend/summary/all",
"schedule": "0 16 * * 1"
},
{
"path": "/api/reply-tracker/disable-unused-auto-draft",
"schedule": "0 3 * * *"
}
]
Here are some easy ways to run cron jobs. Upstash is a free, easy option. I could never get the Vercel vercel.json. Open to PRs if you find a fix for that.
Python tool for converting files and office documents to Markdown.
MarkItDown


[!TIP] MarkItDown now offers an MCP (Model Context Protocol) server for integration with LLM applications like Claude Desktop. See markitdown-mcp for more information.
[!IMPORTANT] Breaking changes between 0.0.1 to 0.1.0:
- Dependencies are now organized into optional feature-groups (further details below). Use
pip install 'markitdown[all]'to have backward-compatible behavior.- convert_stream() now requires a binary file-like object (e.g., a file opened in binary mode, or an io.BytesIO object). This is a breaking change from the previous version, where it previously also accepted text file-like objects, like io.StringIO.
- The DocumentConverter class interface has changed to read from file-like streams rather than file paths. No temporary files are created anymore. If you are the maintainer of a plugin, or custom DocumentConverter, you likely need to update your code. Otherwise, if only using the MarkItDown class or CLI (as in these examples), you should not need to change anything.
MarkItDown is a lightweight Python utility for converting various files to Markdown for use with LLMs and related text analysis pipelines. To this end, it is most comparable to textract, but with a focus on preserving important document structure and content as Markdown (including: headings, lists, tables, links, etc.) While the output is often reasonably presentable and human-friendly, it is meant to be consumed by text analysis tools -- and may not be the best option for high-fidelity document conversions for human consumption.
At present, MarkItDown supports:
- PowerPoint
- Word
- Excel
- Images (EXIF metadata and OCR)
- Audio (EXIF metadata and speech transcription)
- HTML
- Text-based formats (CSV, JSON, XML)
- ZIP files (iterates over contents)
- Youtube URLs
- EPubs
- ... and more!
Why Markdown?
Markdown is extremely close to plain text, with minimal markup or formatting, but still provides a way to represent important document structure. Mainstream LLMs, such as OpenAI's GPT-4o, natively "speak" Markdown, and often incorporate Markdown into their responses unprompted. This suggests that they have been trained on vast amounts of Markdown-formatted text, and understand it well. As a side benefit, Markdown conventions are also highly token-efficient.
Installation
To install MarkItDown, use pip: pip install 'markitdown[all]'. Alternatively, you can install it from the source:
git clone [email protected]:microsoft/markitdown.git
cd markitdown
pip install -e 'packages/markitdown[all]'
Usage
Command-Line
markitdown path-to-file.pdf > document.md
Or use -o to specify the output file:
markitdown path-to-file.pdf -o document.md
You can also pipe content:
cat path-to-file.pdf | markitdown
Optional Dependencies
MarkItDown has optional dependencies for activating various file formats. Earlier in this document, we installed all optional dependencies with the [all] option. However, you can also install them individually for more control. For example:
pip install 'markitdown[pdf, docx, pptx]'
will install only the dependencies for PDF, DOCX, and PPTX files.
At the moment, the following optional dependencies are available:
[all]Installs all optional dependencies[pptx]Installs dependencies for PowerPoint files[docx]Installs dependencies for Word files[xlsx]Installs dependencies for Excel files[xls]Installs dependencies for older Excel files[pdf]Installs dependencies for PDF files[outlook]Installs dependencies for Outlook messages[az-doc-intel]Installs dependencies for Azure Document Intelligence[audio-transcription]Installs dependencies for audio transcription of wav and mp3 files[youtube-transcription]Installs dependencies for fetching YouTube video transcription
Plugins
MarkItDown also supports 3rd-party plugins. Plugins are disabled by default. To list installed plugins:
markitdown --list-plugins
To enable plugins use:
markitdown --use-plugins path-to-file.pdf
To find available plugins, search GitHub for the hashtag #markitdown-plugin. To develop a plugin, see packages/markitdown-sample-plugin.
Azure Document Intelligence
To use Microsoft Document Intelligence for conversion:
markitdown path-to-file.pdf -o document.md -d -e "<document_intelligence_endpoint>"
More information about how to set up an Azure Document Intelligence Resource can be found here
Python API
Basic usage in Python:
from markitdown import MarkItDown
md = MarkItDown(enable_plugins=False) # Set to True to enable plugins
result = md.convert("test.xlsx")
print(result.text_content)
Document Intelligence conversion in Python:
from markitdown import MarkItDown
md = MarkItDown(docintel_endpoint="<document_intelligence_endpoint>")
result = md.convert("test.pdf")
print(result.text_content)
To use Large Language Models for image descriptions, provide llm_client and llm_model:
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(llm_client=client, llm_model="gpt-4o")
result = md.convert("example.jpg")
print(result.text_content)
Docker
docker build -t markitdown:latest .
docker run --rm -i markitdown:latest < ~/your-file.pdf > output.md
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
How to Contribute
You can help by looking at issues or helping review PRs. Any issue or PR is welcome, but we have also marked some as 'open for contribution' and 'open for reviewing' to help facilitate community contributions. These are ofcourse just suggestions and you are welcome to contribute in any way you like.
| All | Especially Needs Help from Community | |
|---|---|---|
| Issues | All Issues | Issues open for contribution |
| PRs | All PRs | PRs open for reviewing |
Running Tests and Checks
-
Navigate to the MarkItDown package:
cd packages/markitdown -
Install
hatchin your environment and run tests:pip install hatch # Other ways of installing hatch: https://hatch.pypa.io/dev/install/ hatch shell hatch test(Alternative) Use the Devcontainer which has all the dependencies installed:
# Reopen the project in Devcontainer and run: hatch test -
Run pre-commit checks before submitting a PR:
pre-commit run --all-files
Contributing 3rd-party Plugins
You can also contribute by creating and sharing 3rd party plugins. See packages/markitdown-sample-plugin for more details.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.