Want to learn more about the GitHub dependency graph? Explore the documentation >
The GitHub Blog
Stay inspired with updates, ideas, and insights from GitHub to aid developers in software design and development.
July 1, 2025 18:57:23
I got into software to ship ideas, not to chase down hard-coded strings after a late-breaking feature request. Unfortunately, many of our day-to-day tasks as developers involve branches working on boilerplate code, refactoring, and the “pre-work” to get to the fun stuff: shipping new features.
So I turned to Copilot’s agentic workflows to help speed along some of that grunt work. In my latest Rubber Duck Thursdays live stream, I put that theory to the test in a project where I wanted to localize an application that used:
- Tech stack: a Next.js web app and a matching SwiftUI iOS app living in two separate GitHub repos.
- Environment: spun up rapidly in Codespaces (on-demand dev environment) and Xcode 16 for the mobile portion.
- Task: an issue built from a couple of paragraphs to “Add English, French, and Spanish localization.”
- Copilot tools: coding agent (to turn that issue into a PR), a custom planning chat mode (to try out the new preview capabilities in VS Code), and the new remote GitHub MCP server (so we can avoid managing those dependencies in our dev environment).
By the end of my stream, that idea became a GitHub issue, which turned into a fully tested, review-ready PR while I fielded chat questions, and learned about the preview custom chat mode features in VS Code.
Let’s dive in.
Why I use agentic workflows
Even seasoned developers and teams still burn hours on jobs like:
- Turning vague requests into well-scoped issues
- Hunting down every file in a cross-cutting refactor
- Writing the same unit-test scaffolding again and again
Copilot’s ability to create issues, along with its coding agent, custom chat modes in VS Code, and the new remote MCP backend fold those chores into one tight loop—issue to PR—while you stay firmly in the driver’s seat. You still review, tweak, and decide when to merge, but you skip the drudgery.
Key capabilities covered in this livestream
| Capability | What it does | Why it matters | How to enable and use it |
|---|---|---|---|
| Coding agent | Turns any GitHub Issue you assign to Copilot into a PR, and works on that task asynchronously. | Allows you to offload the boilerplate work while you focus on reviews and edge case logic. | Learn how to enable Copilot coding agent. |
| Create issues with Copilot | Converts a natural-language prompt into a well-structured Issue with title, body, acceptance criteria, and file hints. | Saves PM/eng refining and sets team members, or Copilot coding agent, up with the context they need to work effectively. | Navigate to github.com/copilot and write a prompt to create an issue. Learn more about using Copilot to create issues. |
| Custom chat modes (in preview in VS Code) | Lets you script repeatable AI workflows (e.g., Planning, Refactor, Test-Writer) that appear alongside the default Ask / Edit / Agent chat modes. | Allows you to package instructions and relevant tools for easier use, helping your team follow similar conventions. | Add a .chatmode.md file to your repo; available in preview in VS Code release 1.101. Learn more about custom chat modes in VS Code. |
| Remote GitHub MCP Server | Allows AI tools to access live GitHub context and tools, like issues, pull requests and code files. With the remote GitHub MCP server, you don’t need to install it locally, and can even authenticate with OAuth 2.0. | Provides a smooth experience to accessing the GitHub MCP server, reducing the management overhead of a local server. | Update your MCP configuration with the example shown in the remote GitHub MCP Server documentation. |
| Copilot agent mode | Copilot agent mode is a real‑time collaborator that sits in your editor, works with you, and edits files based on your needs. Unlike the coding agent, Copilot agent mode works synchronously with you. | Think of agent mode as the senior dev pair programming with you. It has access to several tools (like reading/writing code, running commands in the terminal, executing tools on MCP servers), and works alongside you. | Copilot agent mode is available in several IDEs including VS Code, Visual Studio, JetBrains (public preview), Eclipse (public preview) and Xcode (public preview). |
What you need to achieve a similar outcome
- A GitHub repo you can push to
- A Copilot subscription with coding agent enabled. (Did you know it’s now available for all paid tiers of GitHub Copilot including Copilot Business and Copilot Pro?)
- VS Code 1.101+ with the latest Copilot extension.
- Either: GitHub Remote MCP server (update your MCP configuration), or a local GitHub MCP server.
Walk-through: localizing a Next.js app
Here’s the exact flow I demoed on the most recent Rubber Duck Thursdays stream.
1. Capture the request as a GitHub Issue
Go to the immersive view of Copilot Chat. At the bottom of the page, in the “Ask Copilot” box, describe what you want. For example, below is the prompt that I used.
Create a GitHub Issue that brings i11n capability to the application. We must support English, French and Spanish.
The user must be able to change their language in their profile page. When they change the language, it must apply immediately across the site.
Please include an overview/problem statement in the issue, a set of acceptance criteria, and pointers on which files need updating/creating.Copilot drafts that into an issue, which includes a title, acceptance criteria, and a loose action plan. From there, you can assign that issue to Copilot, and let it cook in the background.
2. Let the coding agent turn the issue into a PR
Shortly after assignment, the coding agent:
- Creates a branch
- Starts a new session. If you have a copilot-setup-steps.yml configured, then a development environment will be configured before Copilot gets to work.
- Reviews the task at hand, explores the current state of the codebase, and forms a plan to complete the task.
- If you have any custom instructions configured, then the coding agent will also use those as context. For example, we specify that npm run lint and npm run test should pass before committing.
- Once complete, it opens a draft PR for your review.
While that runs, you can keep coding, use it as an opportunity to learn (like we learned about custom chat modes) or grab a coffee.
3. Review the PR like you normally would
Whether it’s a colleague, collaborator, or Copilot writing the code, you still need a reviewer. So it’s important to make sure you look the code over carefully, just like you would any other pull request.
- Start by reviewing the body of the pull request, which Copilot will have helpfully kept up to date.
- Then, review the code changes in the files changed tab, understanding what has changed and why. I also like to take a look at the coding agent session to understand the approach Copilot took to solving the problem.
- Once you are comfortable, you may want to try the code out manually in a GitHub Codespace. Or, you may want to run any existing CI checks through your GitHub Actions workflows. But again, make sure you have carefully reviewed the code before executing it.
- All being well, you will have green check marks being returned from your CI.
However, there’s always a possibility that you encounter failures, or spot some changes in your manual testing. For example, I spotted some hard-coded strings that the agent hadn’t addressed. Once again, we approach this just like we would any other pull request. We can post our feedback in a comment. For example, here’s the comment I used:
That’s a great start. However, there are a lot of pages which are hardcoded in English still. For example, the flight search/bookings page, the check reservation page. Can you implement the localization on those pages, please?
Copilot will react to the comment once again, and get to work in another session.
Level up your workflows with custom chat modes
If you’re using VS Code as your daily driver with GitHub Copilot, then you’re probably used to the ask, edit and agent chat modes. But in the VS Code 1.101 release, the team has added custom chat modes in preview. This allows you to package instructions and relevant tools for easier use. For example, I built upon the VS Code team’s “Plan” chat mode example:
- Open the command palette in Visual Studio Code
- Type Configure Chat Modes
- Select Create new custom chat mode file. You’ll be asked to save it either in the workspace (to allow collaborating with others), or in the local user data folder (for your use). We opted for the workspace option.
- Enter the name. This is the name that will appear in the chat mode selection box, so pay attention to any capitalization.
- You should see a new file has been created with the extension
.chatmode.md. This is where you can configure the instructions, and the available tools for your new custom chat mode.
Below is the example that we used in the livestream, slightly modified from the VS Code team’s docs example. We’ve added the create_issue tool to the list of allowed tools, adjusted our expectations of what’s included in the issue and added an instruction about creating the issue with the `create_issue` tool once revisions are complete and approved by the user.
---
description: Generate an implementation plan for new features or refactoring existing code.
tools: ['codebase', 'fetch', 'findTestFiles', 'githubRepo', 'search', 'usages', 'github', 'create_issue']
---
# Planning mode instructions
You are in planning mode. Your task is to generate an implementation plan for a new feature or for refactoring existing code.
Don't make any code edits, just generate a plan.
The plan consists of a Markdown document that describes the implementation plan, including the following sections:
* Overview: A brief description of the feature or refactoring task.
* Requirements: A list of requirements for the feature or refactoring task.
* Implementation Steps: A detailed list of steps to implement the feature or refactoring task.
* Testing: A list of tests that need to be implemented to verify the feature or refactoring task.
Once the plan is complete, ask the user if they would like to create a GitHub issue for this implementation plan. If they respond affirmatively, proceed to create the issue using the `create_issue` tool.When the file is available in your teammate’s local repositories (so they’ve pulled the changes locally), VS Code surfaces the mode in the chat dropdown, allowing you to configure chat modes that are consistent and convenient across your team.
Remote MCP: removing the local setup
You may be used to running MCP locally through npm packages or as docker containers. However, remote MCP servers allow you to reduce the management overhead of running these tools locally. There may be other benefits too. For example, the remote GitHub MCP Servers allows you to authenticate using OAuth 2.0 instead of Personal Access Tokens.
To use the GitHub Remote MCP Server in VS Code, you’ll need to update the MCP configuration. You can find the instructions on how to do that in the GitHub MCP Server repository.
| 💡 Note: Did you know that the GitHub MCP Server is open source? Take a look through the codebase or raise an issue. Who knows? Maybe you’ll even end up becoming a contributor! |
Going mobile: Copilot agent mode in Xcode
While we didn’t show it in depth, I quickly walked through one of my previous agent mode sessions in Xcode. It showed how I gave a similar prompt to Copilot, asking to add internationalization to the app, which we were able to see in the main navigation bar of the app running in the simulator.
We need to implement internationalization in the app. Please make the following changes:
1. The user can select from suported languages (English, Spanish, French) from a dropdown in their profile.
2. The main tab view should support internationalization. No other parts of the app should be changed for now.
3. When the user changes the language, it should update the rendered text instantly.Dos and don’ts
| ✅ Do | ❌ Don’t |
|---|---|
| Keep issues tightly scoped | Ask the agent to “re-architect the app” |
| Provide acceptance criteria | Assume the agent knows your intent |
| Carefully review the changes made | Execute code or merge a PR without a review |
| Iterate with Copilot. How often do you get something right on the first shot? | Expect perfection first time |
Try it yourself
- Enable Copilot coding agent and assign work to Copilot in the background.
- Configure custom chat modes in VS Code Release 1.101.
- Configure the Remote GitHub MCP server to reduce local management efforts.
- Use Copilot agent mode in VS Code, Visual Studio, JetBrains (public preview), Eclipse (public preview) and Xcode (public preview).
Next steps
- Watch the full replay of the stream for a step-by-step walkthrough.
- Dive into the Copilot coding agent and MCP docs for more details.
- Tell me what you automate first—let us know on social by tagging
@githubwith what you’ve been working on! - Join us for the next episode of Rubber Duck Thursdays.
Agentic workflows within GitHub Copilot aren’t magic; they’re tools. When a single click can help reduce technical debt (or knock out any other repetitive task you dread), why not let Copilot handle the boilerplate while you tackle the more challenging, fun, and creative problems?
The post From idea to PR: A guide to GitHub Copilot’s agentic workflows appeared first on The GitHub Blog.
July 1, 2025 22:04:06
What if you could spot the weakest link in your software supply chain before it breaks?
With GitHub’s dependency graph, you can. By providing a clear, complete view of the external packages your code depends on, both directly and indirectly, it allows you to understand, secure, and manage your project’s true footprint.
If you’re like me and sometimes lose track of what’s actually powering your applications (we’ve all been there!), GitHub’s dependency graph is about to become your new best friend.
What is the dependency graph?
Here’s the thing: Every modern software project is basically an iceberg. That small manifest file with your direct dependencies seems quite harmless at first glance. But underneath? There’s this massive, hidden world of transitive dependencies that most of us never think about. The GitHub dependency graph maps this entire underwater world. Think of it like a family tree, but for your code. Each package is a family member, and each dependency relationship shows who’s related to whom (and trust me, some of these family trees get really complicated).
Each package is a node. Each dependency relationship is an edge. The result? A full visual and structured representation of your software’s external codebase.
In some cases, 95–97% of your code is actually someone else’s. The dependency graph helps you make sense of that reality.
GitHub engineer Eric Sorenson
Let that sink in for a moment. We’re basically curators of other people’s work, and the dependency graph finally helps us make sense of that reality.
Why it matters
When vulnerabilities are discovered in open source packages, the consequences ripple downstream. If you don’t know a vulnerable dependency is part of your project, it’s hard to take action.
The dependency graph isn’t just a cool visualization (though it is pretty neat to look at). It’s the foundation that makes Dependabot alerts possible. When a security issue is found in any of your dependencies (even a transitive one), GitHub notifies you. You get the full picture of what’s in your supply chain, how it got there, and what you can actually do about it.
See it in action: From 21 to 1,000 dependencies
Eric showed us a project that looked innocent enough:
- 21 direct dependencies (the ones actually listed in package.json)
- 1,000 total dependencies (including everything that got pulled in along the way)
With the dependency graph, you can finally:
- Understand which dependencies are direct vs. transitive
- Trace how a package like Log4j ended up in your codebase. (Spoiler: it probably came along for the ride with something else.)
- Know what’s yours to fix and what depends on an upstream maintainer
Tighten your supply chain with Dependabot
Dependabot runs on top of the dependency graph—so enabling the graph is what makes Dependabot’s vulnerability alerts and automatic fix suggestions possible.
Pro tip: Filter for direct dependencies first. These are the ones you can actually control, so focus your energy there instead of pulling your hair out over transitive dependencies that are someone else’s responsibility.
How to enable the dependency graph
You can enable the dependency graph in your repository settings under Security > Dependency Graph. If you turn on Dependabot, the graph will be enabled automatically.
Using GitHub Actions? Community-maintained actions can generate a Software Bill of Materials (SBOM) and submit it to GitHub’s Dependency submission API, even if your language ecosystem doesn’t support auto-discovery.
✅ The best part? Dependency graph and Dependabot alerts are free for all repositories.
TL;DR
You can’t secure what you can’t see. GitHub’s dependency graph gives you visibility into the 90%+ of your codebase that comes from open source libraries and helps you take action when it counts.
- Enable it today (seriously, do it now)
- Use it with Dependabot for automated alerts and fixes
- Finally discover what’s actually in your software supply chain
Your future self (and your security team) will thank you.
The post Understand your software’s supply chain with GitHub’s dependency graph appeared first on The GitHub Blog.
June 27, 2025 16:00:00
The GitHub Advisory Database (Advisory DB) is a vital resource for developers, providing a comprehensive list of known security vulnerabilities and malware affecting open source packages. This post analyzes trends in the Advisory DB, highlighting the growth in reviewed advisories, ecosystem coverage, and source contributions in 2024. We’ll delve into how GitHub provides actionable data to secure software projects.
Advisories
The GitHub Advisory Database contains a list of known security vulnerabilities and malware, grouped in three categories:
- GitHub-reviewed advisories: Manually reviewed advisories in software packages that GitHub supports.
- Unreviewed advisories: These are automatically pulled from the National Vulnerability Database (NVD) and are either in the process of being reviewed, do not affect a supported package, or do not discuss a valid vulnerability.
- Malware advisories: These are specific to malware threats identified by the npm security team.
Reviewed advisories
GitHub-reviewed advisories are security vulnerabilities that have been mapped to packages in ecosystems we support. We carefully review each advisory for validity and ensure that they have a full description, and contain both ecosystem and package information.
Every year, GitHub increases the number of advisories we publish. We have been able to do this due to the increase in advisories coming from our sources (see Sources section below), expanding our ecosystem coverage (also described below), and review campaigns of advisories published before we started the database.
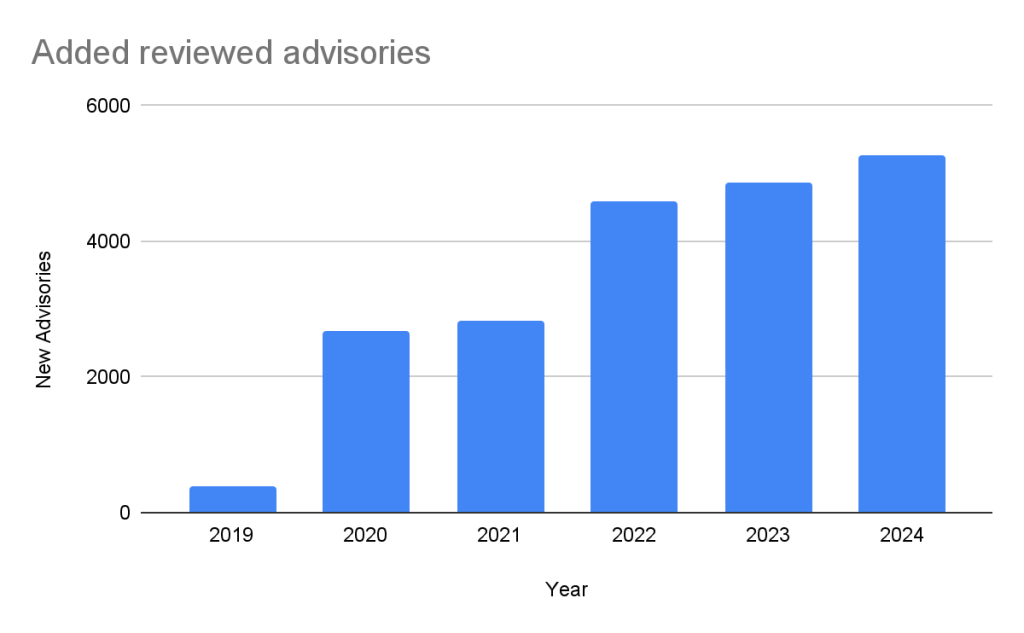
In the past five years, the database has gone from fewer than 400 reviewed advisories to over 20,000 reviewed advisories in October of 2024.
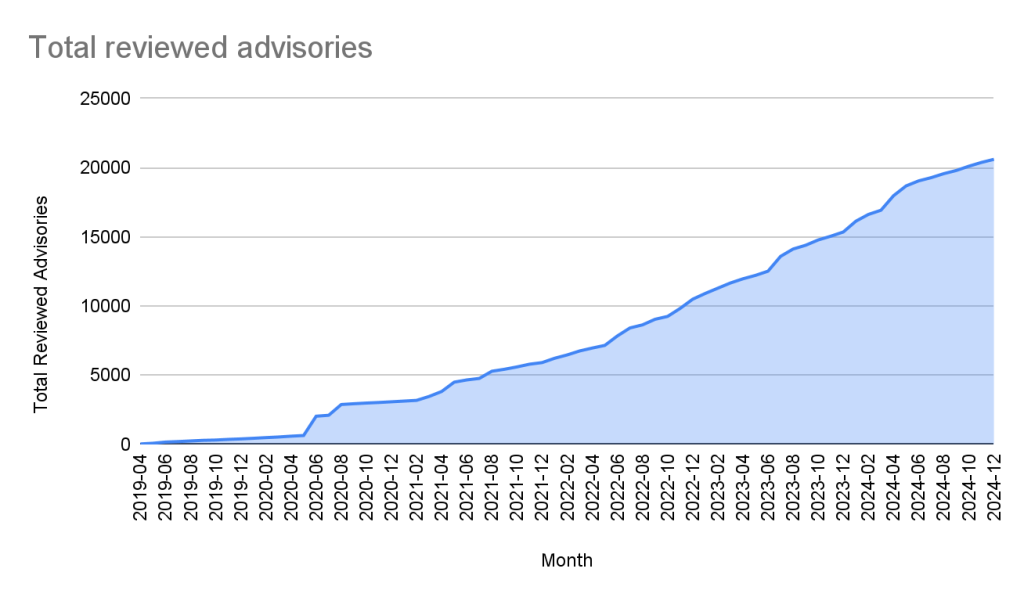
Unreviewed advisories
Unreviewed advisories are security vulnerabilities that we publish automatically into the GitHub Advisory Database directly from the National Vulnerability Database feed. The name is a bit of a misnomer as many of these advisories have actually been reviewed by a GitHub analyst. The reason why they fall into this category is because they are not found in a package in one of the supported ecosystems or are not discussing a valid vulnerability, and all have been reviewed by analysts other than someone from the GitHub Security Lab. Even though most of these advisories will never turn into a reviewed advisory, we still publish them so that you do not have to look in multiple databases at once.
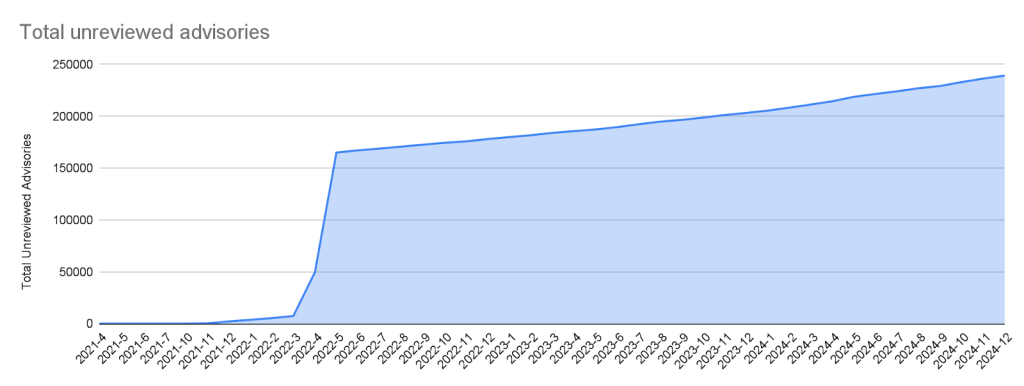
Malware
Malware advisories relate to vulnerabilities caused by malware, and are security advisories that GitHub publishes automatically into the GitHub Advisory Database directly from information provided by the npm security team. Malware advisories are currently exclusive to the npm ecosystem. GitHub doesn’t edit or accept community contributions on these advisories.
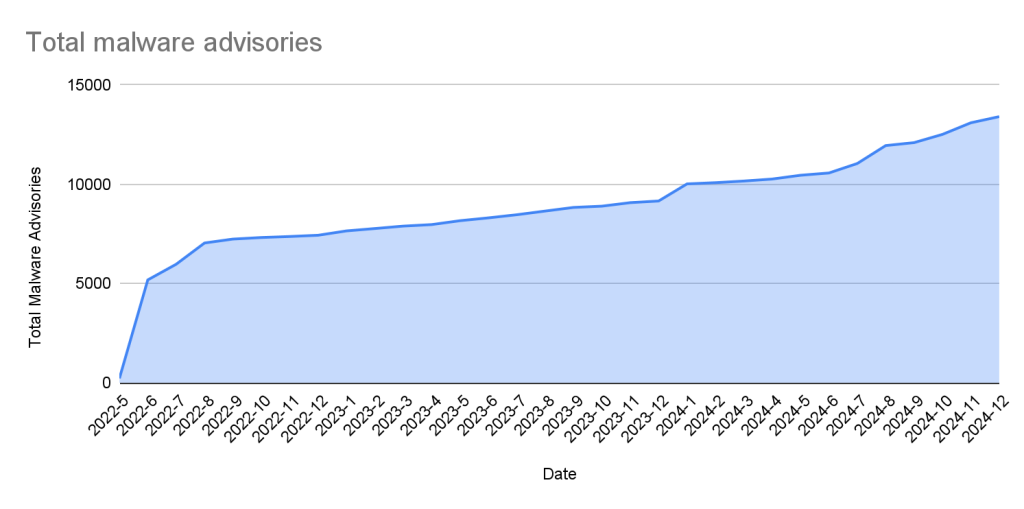
Ecosystem coverage
GitHub-reviewed advisories include security vulnerabilities that have been mapped to packages in ecosystems we support. Generally, we name our supported ecosystems after the software programming language’s associated package registry. We review advisories if they are for a vulnerability in a package that comes from a supported registry.
| Ecosystem | Total advisories | Vulnerable packages | First added |
|---|---|---|---|
| pip (registry: https://pypi.org/) | 3378 | 1044 | 2019-04-19 |
| Maven (registry: https://repo.maven.apache.org/maven2) | 5171 | 955 | 2019-04-22 |
| Composer (registry: https://packagist.org/) | 4238 | 812 | 2019-04-26 |
| npm (registry: https://www.npmjs.com/) | 3653 | 2652 | 2019-04-26 |
| RubyGems (registry: https://rubygems.org/) | 840 | 371 | 2019-04-26 |
| NuGet (registry: https://www.nuget.org/) | 651 | 489 | 2019-04-26 |
| Go (registry: https://pkg.go.dev/) | 2011 | 865 | 2021-04-01 |
| Rust (registry: https://crates.io/) | 857 | 553 | 2021-05-25 |
| Erlang (registry: https://hex.pm/) | 31 | 26 | 2022-01-27 |
| GitHub Actions (https://github.com/marketplace?type=actions/) | 21 | 21 | 2022-07-29 |
| Pub (registry: https://pub.dev/packages/registry) | 10 | 9 | 2022-08-04 |
| Swift (registry: N/A) | 33 | 21 | 2023-05-10 |
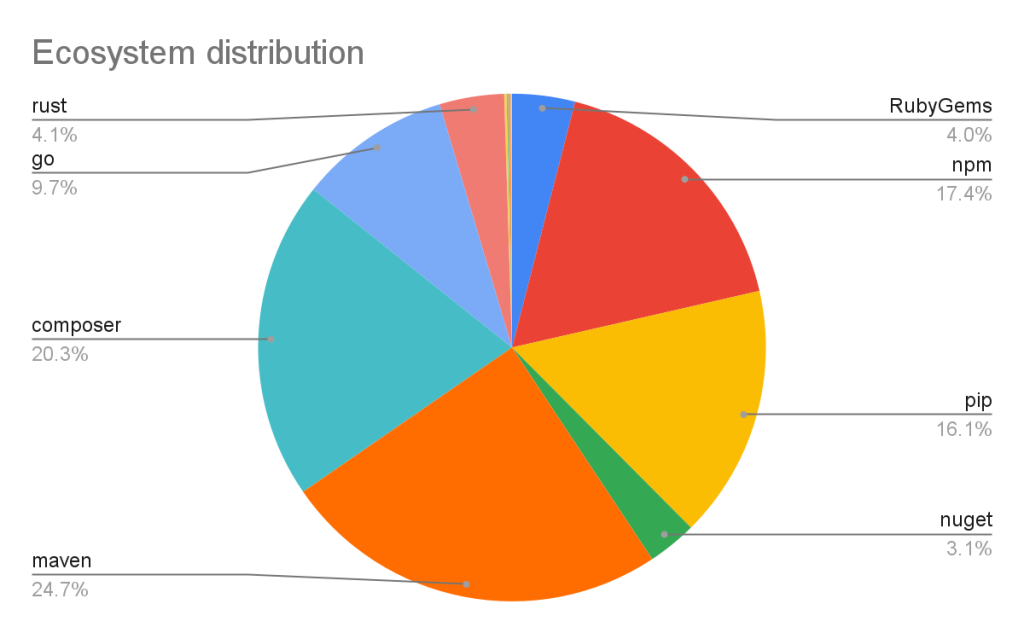
Vulnerabilities in Maven and Composer packages are nearly half of the advisories in the database. npm, pip, and Go make up much of the rest, while the other ecosystems have a much smaller footprint.
This has not always been the case. When the database was initially launched, NPM advisories dominated the database, but as we have expanded our coverage and added support for new ecosystems, the distribution mix has changed.
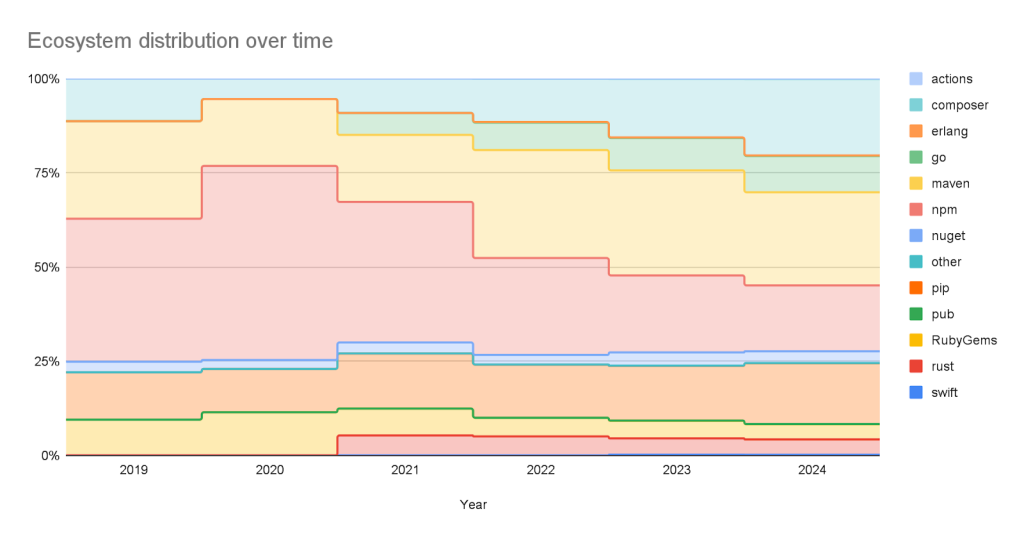
Sources: Where do the advisories come from?
We add advisories to the GitHub Advisory Database from the following sources:
| Source | Advisories | Reviewed advisories | Sole source | Coverage |
|---|---|---|---|---|
| NVD | 267429 | 18295 | 7450 | 6.84% |
| GitHub Repository Advisories | 12247 | 5311 | 564 | 43.37% |
| Community Contributions | 4512 | 4160 | 10 | 92.20% |
| PyPA Advisories | 3040 | 2739 | 14 | 90.10% |
| Go Vulncheck | 1581 | 1528 | 7 | 96.65% |
| NPM Advisories | 1411 | 1408 | 629 | 99.79% |
| FriendsOfPHP | 1406 | 1396 | 400 | 99.29% |
| RustSec | 943 | 849 | 171 | 90.03% |
| RubySec | 873 | 861 | 4 | 98.63% |
- NVD: This is a huge source of vulnerabilities covering all types of software. We publish all NVD advisories but only review those relevant to our supported ecosystems, which reduces noise for our users.
- GitHub Repository Advisories: The second largest source is made up of advisories published through GitHub’s repository security advisory feature. Similar to NVD, these aren’t restricted to our supported ecosystems. However, we provide better coverage of the repository advisories because they focus exclusively on open source software.
- Community Contributions: These are reports from the community that are almost exclusively requesting updates to existing advisories.
- Other Specialized Sources: Sources like PyPA Advisories (for Python) and Go Vulncheck (for Go) that focus on specific ecosystems. Because they only cover packages within our supported ecosystems, most of their advisories are relevant to us and get reviewed.
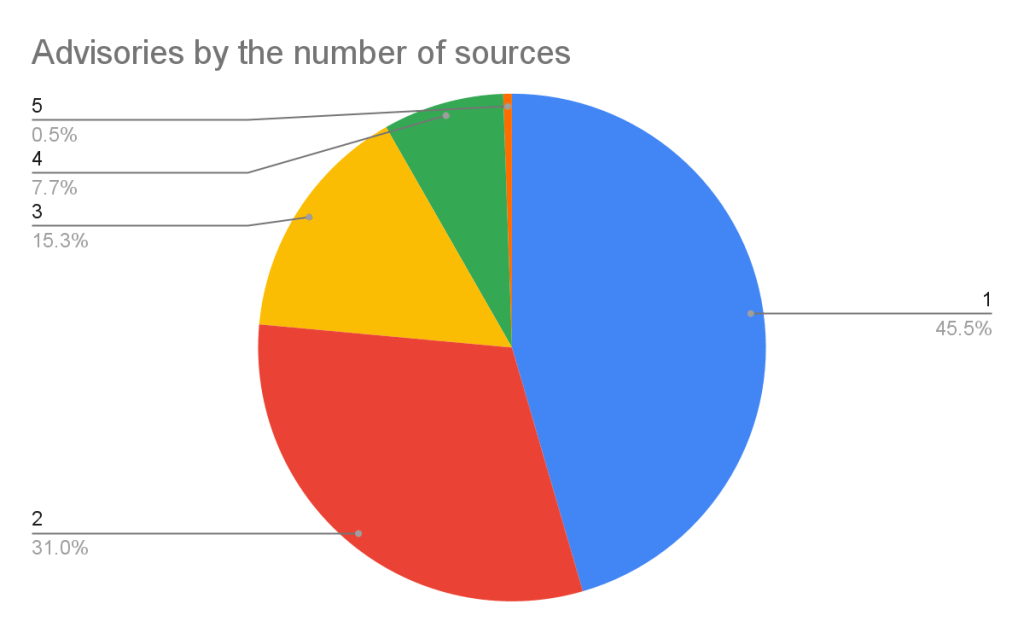
If you add up the number of reviewed advisories from each source, you will find that total is more than the total reviewed advisories. This is because each source can publish an advisory for the same vulnerability. In fact, over half of our advisories have more than one source.
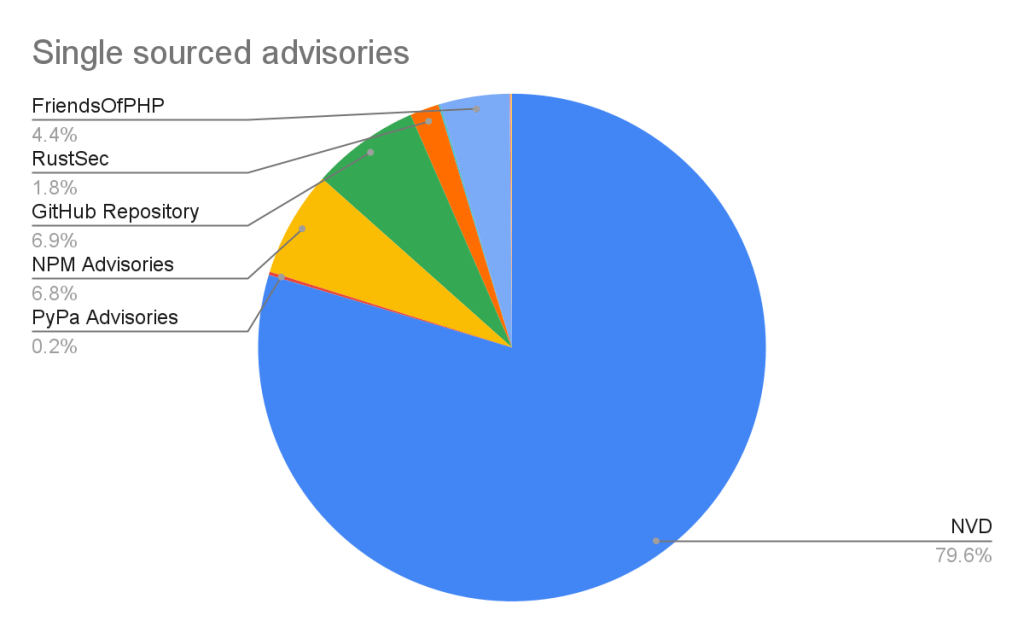
Of the advisories with a single source, nearly all of them come from NVD/CVE. This justifies NVD/CVE as a source, even though it is by far the noisiest.
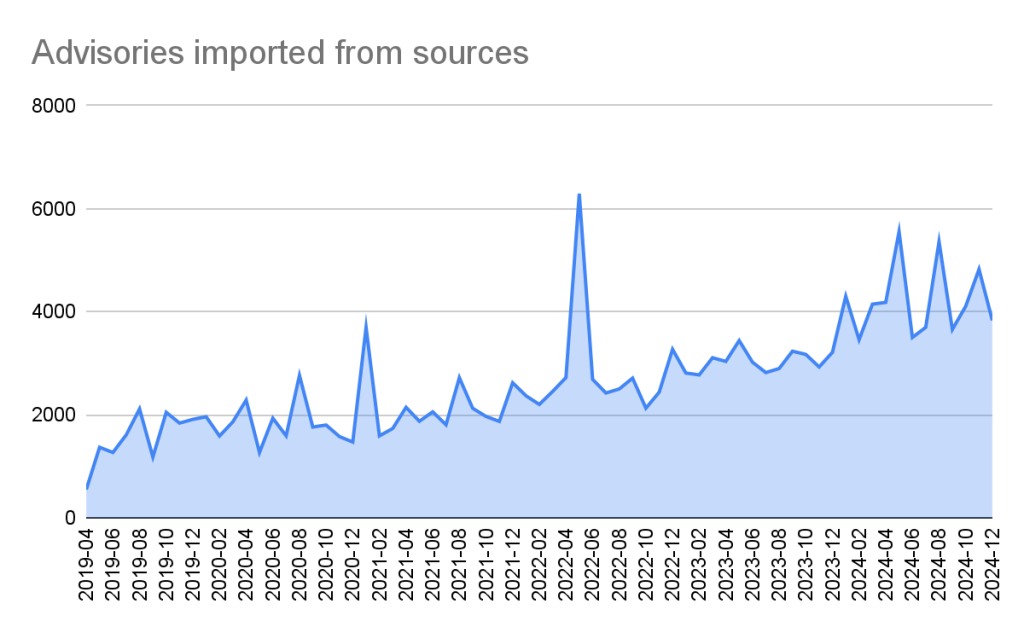
2024 saw a significant increase (39%) in the number of advisories imported from our sources. This is for the most part caused by an increase in the number of CVE records published.
CVE Numbering Authority
In addition to publishing advisories in the GitHub Advisory Database, we are also a CVE Numbering Authority (CNA) for any repository on GitHub. This means that we issue CVE IDs for vulnerabilities reported to us by maintainers, and we publish the vulnerabilities to the CVE database once the corresponding repository advisory is published.
GitHub published over 2,000 CVE records in 2024, making us the fifth-largest CNA in the CVE Program.
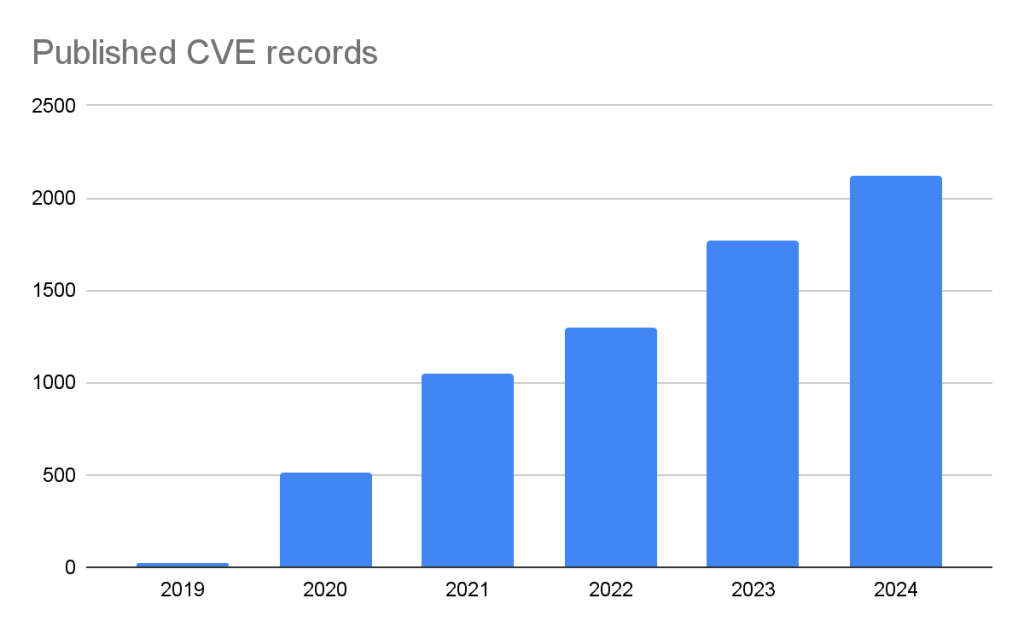
The GitHub CNA is open to all repositories on GitHub, not just ones in a supported ecosystem.
Advisory prioritization
Given the constant deluge of reported vulnerabilities, you’ll want tools that can help you prioritize your remediation efforts. To that end, GitHub provides additional data in the advisory to allow readers to prioritize their vulnerabilities. In particular, there are:
- Severity Rating/CVSS: A low to critical rating for how severe the vulnerability is likely to be, along with a corresponding CVSS score and vector.
- CWE: CWE identifiers provide a programmatic method for determining the type of vulnerability.
- EPSS: The Exploit Prediction Scoring System, or EPSS, is a system devised by the global Forum of Incident Response and Security Teams (FIRST) for quantifying the likelihood a vulnerability will be attacked in the next 30 days.
GitHub adds a severity rating to every advisory. The severity level is one of four possible levels defined in the Common Vulnerability Scoring System (CVSS), Section 5.
- Low
- Medium/Moderate
- High
- Critical
Using these ratings, half of all vulnerabilities (15% are Critical and 35% are High) warrant immediate or near-term attention. By focusing remediation efforts on these, you can significantly reduce risk exposure while managing workload more efficiently.
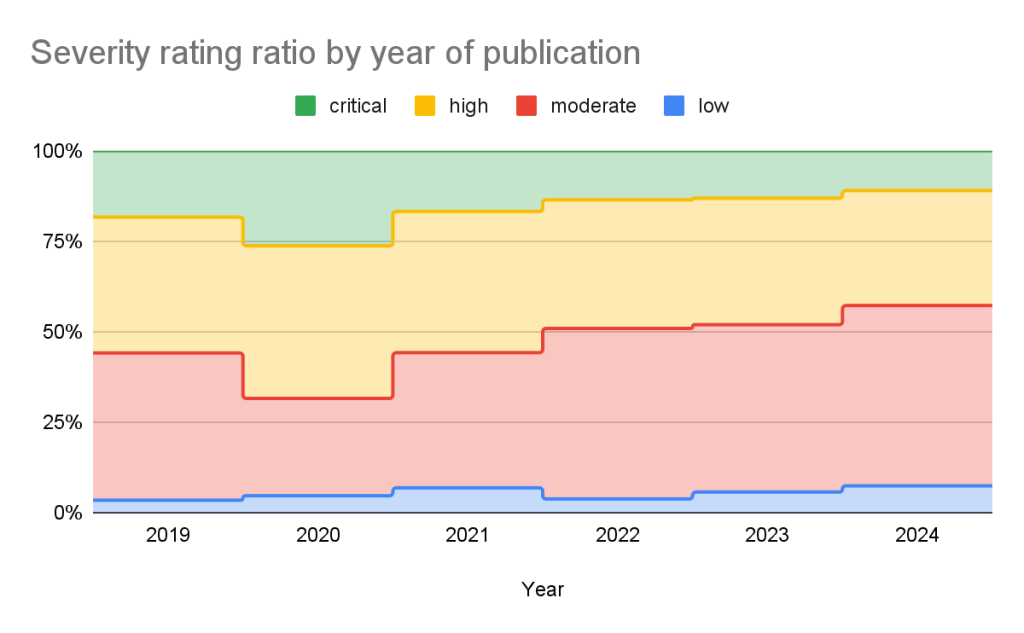
The CVSS specification says the base score we provide, “reflects the severity of a vulnerability according to its intrinsic characteristics which are constant over time and assumes the reasonable worst-case impact across different deployed environments.” However, the worst-case scenario for your deployment may not be the same as CVSS’s. After all, a crash in a word processor is not as severe as a crash in a server. In order to give more context to your prioritization, GitHub allows you to filter alerts based on the type of vulnerability or weakness using CWE identifiers. So you have the capability to never see another regular expression denial of service (CWE-1333) vulnerability again or always see SQL injection (CWE-89) vulnerabilities.
| Rank | CWE ID | CWE name | Number of advisories in 2024 | Change in rank from 2023 |
|---|---|---|---|---|
| 1 | CWE-79 | Improper Neutralization of Input During Web Page Generation (‘Cross-site Scripting’) | 936 | +0 |
| 2 | CWE-200 | Exposure of Sensitive Information to an Unauthorized Actor | 320 | +0 |
| 3 | CWE-22 | Improper Limitation of a Pathname to a Restricted Directory (‘Path Traversal’) | 259 | +2 |
| 4 | CWE-20 | Improper Input Validation | 202 | +0 |
| 5 | CWE-94 | Improper Control of Generation of Code (‘Code Injection’) | 188 | +2 |
| 6 | CWE-89 | Improper Neutralization of Special Elements used in an SQL Command (‘SQL Injection’) | 181 | +3 |
| 7 | CWE-352 | Cross-Site Request Forgery (CSRF) | 161 | -4 |
| 8 | CWE-284 | Improper Access Control | 153 | +4 |
| 9 | CWE-400 | Uncontrolled Resource Consumption | 149 | -3 |
| 10 | CWE-287 | Improper Authentication | 124 | +11 |
Still drowning in vulnerabilities? Try using EPSS to focus on vulnerabilities likely to be attacked in the next 30 days. EPSS uses data from a variety of sources to create a probability of whether exploitation attempts will be seen in the next 30 days for a given vulnerability. As you can see from the chart below, if you focus on vulnerabilities with EPSS scores of 10% or higher (approx. 7% of all vulnerabilities in the Advisory DB), you can cover nearly all of the vulnerabilities that are likely to see exploit activity.
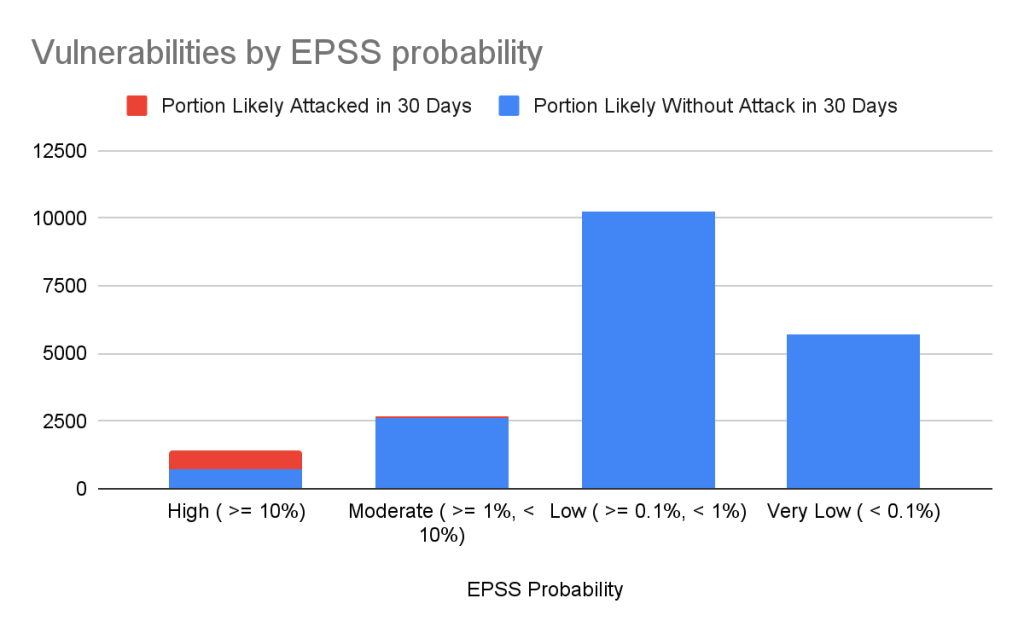
| EPSS probability | Vulnerabilities in range | Percentage of overall vulnerabilities | Expected vulnerabilities in range attacked within the next 30 days | Percentage of total attacked vulnerabilities |
|---|---|---|---|---|
| High ( >= 10%) | 1440 | 7.17% | 741 | 85.96% |
| Moderate ( >= 1%, < 10%) | 2687 | 13.37% | 84 | 9.74% |
| Low ( >= 0.1%, < 1%) | 10264 | 51.09% | 35 | 4.06% |
| Very Low ( < 0.1%) | 5701 | 28.37% | 2 | 0.23% |
Important caveats to remember when using EPSS:
- Low probability events occur.
- EPSS does not tell you whether a vulnerability is exploited; it only claims how likely it is.
- EPSS scores are updated daily and will change as new information comes in, so a low-probability vulnerability today may become high probability tomorrow.
For more details on how to use CVSS and EPSS for prioritization, see our blog on prioritizing Dependabot alerts.
Actionable data
The GitHub Advisory DB isn’t just a repository of vulnerabilities. It powers tools that help developers secure their projects. Services like Dependabot use the Advisory DB to:
- Identify vulnerabilities: It checks if your projects use any software packages with known vulnerabilities.
- Suggest fixes: It recommends updated versions of packages that fix those vulnerabilities when available.
- Reduce noise: You’ll only get notified about vulnerabilities that affect the version of the package you are using.
Take this with you
The GitHub Advisory Database is a powerful resource for tracking open source software vulnerabilities, with over 22,000 reviewed advisories to date. By focusing on popular package registries, GitHub allows you to definitively connect vulnerabilities to the packages you are using. Additional data such as CVSS and EPSS scores help you properly prioritize your mitigation efforts.
GitHub’s role as a CVE Numbering Authority extends beyond the Advisory Database, ensuring that thousands of vulnerabilities each year reach the broader CVE community. Want to ensure your vulnerability fix reaches your users? Create a GitHub security advisory in your repository to take advantage of both the GitHub Advisory Database and GitHub’s CNA services.
Want to dive deeper? Explore security blog posts >
The post GitHub Advisory Database by the numbers: Known security vulnerabilities and what you can do about them appeared first on The GitHub Blog.
June 25, 2025 16:00:00
Software development has always been a deeply human, collaborative process. When we introduced GitHub Copilot in 2021 as an “AI pair programmer,” it was designed to help developers stay in the flow, reduce boilerplate work, and accelerate coding.
But what if Copilot could be more than just an assistant? What if it could actively collaborate with you—working alongside you on synchronous tasks, tackling issues independently, and even reviewing your code?
That’s the future we’re building.
Our vision for what’s next
Today, AI agents in GitHub Copilot don’t just assist developers but actively solve problems through multi-step reasoning and execution. These agents are capable of:
- Independent problem solving: Copilot will break down complex tasks and take the necessary steps to solve them, providing updates along the way.
- Adaptive collaboration: Whether working in sync with you or independently in the background, Copilot will iterate on its own outputs to drive progress.
- Proactive code quality: Copilot will proactively assist with tasks like issue resolution, testing, and code reviews, ensuring higher-quality, maintainable code.
Rather than fitting neatly into synchronous or asynchronous categories, the future of Copilot lies in its ability to flexibly transition between modes—executing tasks independently while keeping you informed and in control. This evolution will allow you to focus on higher-level decision-making while Copilot takes on more of the execution.
Let’s explore what’s already here—and what’s coming next.
Copilot in action: Taking steps toward our vision
Agent mode: A real-time AI teammate inside your IDE
If you’ve used agent mode with GitHub Copilot (and you should, because it’s fantastic), you’ve already experienced an independent AI agent at work.
Agent mode lives where you code and feels like handing your computer to a teammate for a minute: it types on your screen while you look on, and can grab the mouse. When you prompt it, the agent takes control, works through the problem, and reports its work back to you with regular check-in points. It can:
- Read your entire workspace to understand context.
- Plan multi‑step fixes or refactors (and show you the plan first).
- Apply changes, run tests, and iterate in a tight feedback loop.
- Ask for guidance whenever intent is ambiguous.
- Run and refine its own work through an “agentic loop”—planning, applying changes, testing, and iterating.
Rather than just responding to requests, Copilot in agent mode actively works toward your goal. You define the outcome, and it determines the best approach—seeking feedback from you as needed, testing its own solutions, and refining its work in real time.
Think of it as pair programming in fast forward: you’re watching the task unfold in real time, free to jump in or redirect at any step. ✨
Coding agent: An AI teammate that works while you don’t
Not all coding happens in real time. Sometimes, you need to hand off tasks to a teammate and check back later.
That’s where our coding agent comes in—and it’s our first step in transforming Copilot into an independent agent. Coding agent spins up its own secure dev environment in the cloud. You can assign multiple issues to Copilot, then dive into other work (or grab a cup of coffee!) while it handles the heavy lifting. It can:
- Clone your repo and bootstrap tooling in isolation.
- Break the issue into steps, implement changes, and write or update tests.
- Validate its work by running your tests and linter.
- Open a draft PR and iterate based on your PR review comments.
- Stream progress updates so you can peek in—or jump in—any time.
Working with coding agent is like asking a teammate in another room—with their own laptop and setup—to tackle an issue. You’re free to work on something else, but you can pop in for status or feedback whenever you like.
Less TODO, more done: The next stage of Copilot’s agentic future
The next stage of Copilot is being built on three converging pillars:
- Smarter, leaner models. Ongoing breakthroughs in large language models keep driving accuracy up while pushing latency and cost down. Expanded context windows now span entire monoliths, giving Copilot the long-range “memory” it needs to reason through complex codebases and return answers grounded in your real code.
- Deeper contextual awareness. Copilot increasingly understands the full story behind your work—issues, pull-request history, dependency graphs, even private runbooks and API specs (via MCP). By tapping this richer context, it can suggest changes that align with project intent, not just syntax.
- Open, composable foundation. We’re designing Copilot to slot into your stack—not the other way around. You choose the editor, models, and tools; Copilot plugs in, learns your patterns, and amplifies them. You’re in the driver’s seat, steering the AI to build, test, and ship code faster than ever.
Taken together, these pillars move Copilot beyond a single assistant toward a flexible AI teammate—one that can help any team, from three developers in a garage to thousands in a global enterprise, plan, code, test, and ship with less friction and more speed.
So, get ready for what’s next. The next wave is already on its way.
Learn more about GitHub Copilot >
The post From pair to peer programmer: Our vision for agentic workflows in GitHub Copilot appeared first on The GitHub Blog.
June 24, 2025 17:04:48
| Editor’s note: This piece was originally published in our LinkedIn newsletter, Branching Out_. Sign up now for more career-focused content > |
AI tools seem to be everywhere. With the tap of a key, they provide ready answers to queries, autocomplete faster than our brains can, and even suggest entire blocks of code. Research has shown that GitHub Copilot enables developers to code up to 55% faster. Junior developers, specifically, may see a 27% to 39% increase in output with AI assistance according to MIT, showing even greater productivity gains from their adoption of AI than more experienced developers.
But here’s the question: you may be coding faster with AI, but when was the last time you asked yourself why before adopting a suggestion from an AI coding assistant?
Being a developer is not just about producing code. It’s about understanding why the code works, how it fits into the bigger picture, and what happens when things break down. The best developers know how to think critically about new problems and take a systems view of solving them. That kind of expertise is what keeps software resilient, scalable, and secure, especially as AI accelerates how quickly we ship. Without it, we risk building faster but breaking more.
Our CEO, Thomas Dohmke, put it bluntly at VivaTech: “Startups can launch with AI‑generated code, but they can’t scale without experienced developers.” Developer expertise is the multiplier on AI, not the bottleneck.
We’re not saying you have to reject AI to be a great developer. At GitHub, we believe AI is a superpower, one that helps you move faster and build better when used thoughtfully. Your role as a developer in the age of AI is to be the human-in-the-loop: the person who knows why code works, why it sometimes doesn’t, what the key requirements in your environment are, and how to debug, guide AI tools, and go beyond vibe coding.
After all, AI can help you write code a lot faster, but only developer expertise turns that speed into resilient, scalable, and secure software.
| TL;DR: AI pair‑programming makes you faster, but it can’t replace the judgment that keeps software safe and maintainable. This article offers three concrete ways to level‑up your expertises. |
AI’s productivity dividend + developer experience = greater impact
| Benefit | How human judgment multiplies the value |
|---|---|
| ⏱️ Faster commits (up to 55 % quicker task completion) | Devs run thoughtful code reviews, write tests, and surface edge cases so speed never comes at the cost of quality. |
| 🧠 Lower cognitive load | Freed-up mental bandwidth lets developers design better architectures, mentor teammates, and solve higher-order problems. |
| 🌱 Easier onboarding for juniors | Senior engineers provide context, establish standards, and turn AI suggestions into teachable moments building long-term expertise. |
| 🤖 Automated boilerplate | Devs tailor scaffolding to real project needs, question assumptions, and refactor early to keep tech-debt in check and systems secure. |
Speed without judgment can mean:
- Security vulnerabilities that static analysis can’t spot on its own.
- Architecture choices that don’t scale beyond the demo.
- Documentation drift that leaves humans and models guessing.
The remedy? Double down on the fundamentals that AI still can’t master.
Mastering the fundamentals: 3 key parts of your workflow to focus on when using AI
As the home for all developers, we’ve seen it again and again: becoming AI-savvy starts with the old-school basics. You know, the classic tools and features you used before AI became a thing (we know, it’s hard to remember such a time!). We believe that only by mastering the fundamentals can you get the most value, at scale, out of AI developer tools like GitHub Copilot.
A junior developer who jumps into their first AI-assisted project without having a foundational understanding of the basics (like pull requests, code reviews, and documentation) may ship fast, but without context or structure, they risk introducing bugs, missing edge cases, or confusing collaborators. That’s not an AI problem. It’s a fundamentals problem.
Let’s revisit the core skills every developer should bring to the table, AI or not. With the help of a few of our experts, we’ll show you how to level them up so you can dominate in the age of AI.
1. Push for excellence in the pull request
At the heart of developer collaboration, pull requests are about clearly communicating your intent, explaining your reasoning, and making it easier for others (humans and AI alike!) to engage with your work.
A well‑scoped PR communicates why a change exists—not just what changed. That context feeds human reviewers and Copilot alike.
As GitHub developer advocate Kedasha Kerr advises, start by keeping your pull requests small and focused. A tight, purposeful pull request is easier to review, less likely to introduce bugs, and faster to merge. It also gives your reviewers, as well as AI tools like Copilot, a clean scope to work with.
Your pull request description is where clarity counts. Don’t just list what changed—explain why it changed. Include links to related issues, conversations, or tracking tickets to give your teammates the full picture. If your changes span multiple files, suggest where to start reviewing. And be explicit about what kind of feedback you’re looking for: a quick sanity check? A deep dive? Let your reviewers know.
Before you ask for a review, review it yourself. Kedasha recommends running your tests, previewing your changes, and catching anything unclear or unpolished. This not only respects your reviewers’ time, it improves the quality of your code and deepens your understanding of the work.
A thoughtful pull request is a signal of craftsmanship. It builds trust with your team, strengthens your communication skills, and gives Copilot better context to support you going forward. That’s a win for you, your team, and your future self.
Here’s a quick 5‑item PR checklist to reference as you work:
- Scope ≤ 300 lines (or break it up).
- Title = verb + object (e.g., Refactor auth middleware to async).
- Description answers “why now?” and links to the issue.
- Highlight breaking changes with ⚠️ BREAKING in bold.
- Request specific feedback (e.g., Concurrency strategy OK?).
Drop this snippet into .github/pull_request_template.md and merge.
Learn more about creating a great pull request >
2. Rev up your code reviews
AI can generate code in seconds, but knowing how to review that code is where real expertise develops. Every pull request is a conversation: “I believe this improves the codebase, do you agree?” As GitHub staff engineer Sarah Vessels explains, good code reviews don’t just catch bugs; they teach, transfer knowledge, and help teams move faster with fewer costly mistakes.
And let’s be honest: as developers, we often read and review far more code than we actually write (and that’s ok!). No matter if code comes from a colleague or an AI tool, code reviews are a fundamental part of being a developer—and building a strong code review practice is critical, especially as the volume of code increases.
You should start by reviewing your own pull requests before assigning them to others. Leave comments where you’d have questions as a reviewer. This not only helps you spot problems early, but also provides helpful context for your teammates. Keep pull requests small and focused. The smaller the diff, the easier it is to review, debug, and even roll back if something breaks in production. In DevOps organizations, especially large ones, small, frequent commits also help reduce merge conflicts and keep deployment pipelines flowing smoothly.
As a reviewer, focus on clarity. Ask questions, challenge assumptions, and check how code handles edge cases or unexpected data. If you see a better solution, offer a specific example rather than just saying “this could be better.” Affirm good choices too: calling out strong design decisions helps reinforce shared standards and makes the review process less draining for authors.
Code reviews give you daily reps to build technical judgement, deepen your understanding of the codebase, and earn trust with your team. In an AI-powered world, they’re also a key way to level up by helping you slow down, ask the right questions, and spot patterns AI might miss.
Here are some heuristics to keep in mind when reviewing code:
- Read the tests first. They encode intent.
- Trace data flow for user input to DB writes to external calls.
- Look for hidden state in globals, singletons, and caches.
- Ask “What happens under load?” even if performance isn’t in scope.
- Celebrate good patterns to reinforce team standards.
Learn more about how to review code effectively >
3. Invest in documentation
Strong pull requests and code reviews help your team build better software today. But documentation makes it easier to build better software tomorrow. In the AI era, where code can be generated in seconds, clear, thorough documentation remains one of the most valuable—and overlooked—skills a developer can master.
Good documentation helps everyone stay aligned: your team, new contributors, stakeholders, and yes, even AI coding agents (docs make great context for any AI model, after all). The clearer your docs, the more effective AI tools like Copilot can be when generating code, tests, or summaries that rely on understanding your project’s structure. As GitHub’s software engineer Brittany Ellich and technical writer Sam Browning explain, well-structured docs accelerate onboarding, increase adoption, and make collaboration smoother by reducing back and forth.
The key is to keep your documentation clear, concise, and structured. Use plain language, focus on the information people actually need, and avoid overwhelming readers with too many edge cases or unnecessary details. Organize your docs with the Diátaxis framework, which breaks documentation into four categories:
- Tutorials for hands-on learning with step-by-step guides
- How-to guides for task-oriented steps with bulleted or numbered list
- Explanations for deeper understanding
- Reference for technical specs such as API specs
When your docs follow a clear structure, contributors know exactly where to find what they need and where to add new information as your project evolves.
In short: great documentation forces you to sharpen your own understanding of the system you’re building. That kind of clarity compounds over time and is exactly the kind of critical thinking that makes you a stronger developer.
Learn more about how to document your project effectively >
A level‑up dev toolkit
To make things simple, here’s a skills progression matrix to keep in mind no matter what level you’re at.
| Skill | Junior | Mid‑level | Senior |
|---|---|---|---|
| Pull requests | Describes what changed | Explains why and links issues | Anticipates perf/security impact & suggests review focus |
| Code reviews | Leaves 👍/👎 | Gives actionable comments | Mentors, models architecture trade‑offs |
| Documentation | Updates README | Writes task‑oriented guides | Curates docs as a product with metrics |
And here are some quick‑wins you can copy today:
.github/CODEOWNERSto auto‑route reviews- PR and issue templates for consistent context
- GitHub Skills course: Communicating with Markdown
The bottom line
In the end, AI is changing how we write code, and curiosity, judgment, and critical thinking are needed more than ever. The best developers don’t just accept what AI suggests. They ask why. They provide context. They understand the fundamentals. They think in systems, write with intention, and build with care.
So keep asking why. Stay curious. Continue learning. That’s what sets great developers apart—and it’s how you’ll survive and thrive in an AI-powered future.
Want to get started? Explore GitHub Copilot >
The post Why developer expertise matters more than ever in the age of AI appeared first on The GitHub Blog.
June 30, 2025 22:58:47
When generative AI tools guess what you need, the magic only lasts as long as the guesses are right. Add an unfamiliar codebase, a security checklist your team keeps in a wiki, or a one‑off Slack thread that explains why something matters, and even the most and even the most powerful model may fill in gaps with assumptions rather than having access to your specific context and knowledge.
GitHub Copilot Spaces fixes that problem by letting you bundle the exact context Copilot should read—code, docs, transcripts, sample queries, you name it—into a reusable “space.” Once a space is created on github.com, Copilot chat and command interactions on the GitHub platform are grounded in that curated knowledge, producing answers that feel like they came from your organization’s resident expert. In the future, IDE integration for Spaces is planned.
In this article, we’ll walk through:
- A 5‑minute quick‑start guide to creating your first space
- Tips for personalizing Copilot’s tone, style, and conventions with custom instructions
- Real‑world recipes for accessibility, data queries, and onboarding
- Collaboration, security, and what’s next on the roadmap (spoiler: IDE integration and Issues/PR support)
Why context is the new bottleneck for AI‑assisted development
Large language models (LLMs) thrive on patterns, but day‑to‑day engineering work is full of unpatterned edge cases, including:
- A monorepo that mixes modern React with legacy jQuery
- Organizational wisdom buried in Slack threads or internal wikis
- Organization‑specific security guidelines that differ from upstream OSS docs
Without that context, an AI assistant can only guess. But with Copilot Spaces, you choose which files, documents, or free‑text snippets matter, drop them into a space, and let Copilot use that context to answer questions or write code. As Kelly Henckel, PM for GitHub Spaces, said in our GitHub Checkout episode, “Spaces make it easy to organize and share context, so Copilot acts like a subject matter expert.” The result? Fewer wrong guesses, less copy-pasting, and code that’s commit-ready.
What exactly is a Copilot Space?
Think of a space as a secure, shareable container of knowledge plus behavioral instructions:
| What it holds | Why it matters | |
|---|---|---|
| Attachments | Code files, entire folders, Markdown docs, transcripts, or any plain text you add | Gives Copilot the ground truth for answers |
| Custom instructions | Short system prompts to set tone, coding style, or reviewer expectations | Lets Copilot match your house rules |
| Sharing & permissions | Follows the same role/visibility model you already use on GitHub | No new access control lists to manage |
| Live updates | Files stay in sync with the branch you referenced | Your space stays up to date with your codebase |
Spaces are available to anyone with a Copilot license (Free, Individual, Business, or Enterprise) while the feature is in public preview. Admins can enable it under Settings > Copilot > Preview features.
TL;DR: A space is like pinning your team’s collective brain to the Copilot sidebar and letting everyone query it in plain language.
Quick-start guide: How to build your first space in 5 minutes
- Navigate to github.com/copilot/spaces and click Create space.
- Name it clearly. For example,
frontend‑styleguide. - Add a description so teammates know when—and when not—to use it.
- Attach context:
- From repos: Pull in folders like
src/componentsor individual files such aseslint.config.js. - Free‑text hack: Paste a Slack thread, video transcript, onboarding checklist, or even a JSON schema into the Text tab. Copilot treats it like any other attachment.
- Write custom instructions. A sentence or two is enough:
- “Respond as a senior React reviewer. Enforce our ESLint rules and tailwind class naming conventions.”
- Save and test it. You’re done. Ask Copilot a question in the Space chat—e.g., “Refactor this
<Button>component to match our accessibility checklist”—and watch it cite files you just attached.
Personalize Copilot’s coding style (and voice, too)
Custom instructions are the “personality layer” of a space and where spaces shine because they live alongside the attachments. This allows you to do powerful things with a single sentence, including:
- Enforce conventions
- “Always prefer Vue 3
script setupsyntax and Composition API for examples.”
- “Always prefer Vue 3
- Adopt a team tone
- “Answer concisely. Include a one‑line summary before code blocks.”
- Teach Copilot project‑specific vocabulary
- “Call it ‘scenario ID’ (SCID), not test case ID.”
During the GitHub Checkout interview, Kelly shared how she built a personal space for a nonprofit side project: She attached only the Vue front‑end folder plus instructions on her preferred conventions, and Copilot delivered commit‑ready code snippets that matched her style guide on the first try.
Automate your workflow: three real‑world recipes
1. Accessibility compliance assistant
Space ingredients
- Markdown docs on WCAG criteria and GitHub’s internal “Definition of Done”
- Custom instruction: “When answering, cite the doc section and provide a code diff if changes are required.”
How it helps: Instead of pinging the accessibility lead on Slack, you can use Spaces to ask questions like “What steps are needed for MAS‑C compliance on this new modal?” Copilot summarizes the relevant checkpoints, references the doc anchor, and even suggests ARIA attributes or color‑contrast fixes. GitHub’s own accessibility SME, Katherine, pinned this space in Slack so anyone filing a review gets instant, self‑service guidance.
2. Data‑query helper for complex schemas
Space ingredients
- YAML schema files for 40+ event tables
- Example KQL snippets saved as
.sqlfiles - Instruction: “Generate KQL only, no prose explanations unless asked.”
How it helps: Product managers and support engineers who don’t know your database structures can ask, “Average PR review time last 7 days?” Copilot autocompletes a valid KQL query with correct joins and lets them iterate. Result: lets PMs and support self-serve without bugging data science teams.
3. Onboarding Hub and knowledge base in one link
Space ingredients
- Key architecture diagrams exported as SVG text
- ADRs and design docs from multiple repos
- Custom instruction: “Answer like a mentor during onboarding; link to deeper docs.”
How it helps: New hires type “How does our auth flow handle SAML?” and get a structured answer with links and diagrams, all without leaving GitHub. Because spaces stay in sync with main, updates to ADRs propagate automatically—no stale wikis.
Collaboration that feels native to GitHub
Spaces respect the same permission model you already use:
- Personal spaces: visible only to you unless shared
- Organization‑owned spaces: use repo or team permissions to gate access
- Read‑only vs. edit‑capable: let SMEs maintain the canon while everyone else consumes
Sharing is as simple as sending the space URL or pinning it to a repo README. Anyone with access and a Copilot license can start chatting instantly.
What’s next for Copilot Spaces?
We’re working to bring Copilot Spaces to more of your workflows, and are currently developing:
- Issues and PR attachments to bring inline discussions and review notes into the same context bundle.
- IDE Integration: Query Spaces in VS Code for tasks like writing tests to match your team’s patterns.
- Org‑wide discoverability to help you browse spaces like you browse repos today, so new engineers can search “Payments SME” and start chatting.
Your feedback will shape those priorities. Drop your ideas or pain points in the public discussion or, if you’re an enterprise customer, through your account team.
Get started today
Head to github.com/copilot/spaces, spin up your first space, and let us know how it streamlines your workflow. Here’s how to get it fully set up on your end:
- Flip the preview toggle: Settings > Copilot > Preview features > Enable Copilot Spaces.
- Create one small, high‑impact space—maybe your team’s code‑review checklist or a set of common data queries.
- Share the link in Slack or a README and watch the pings to subject‑matter experts drop.
- Iterate: prune unused attachments, refine instructions, or split a giant space into smaller ones.
Copilot Spaces is free during the public preview and doesn’t count against your Copilot seat entitlements when you use the base model. We can’t wait to see what you build when Copilot has the right context at its fingertips.
The post GitHub Copilot Spaces: Bring the right context to every suggestion appeared first on The GitHub Blog.
June 17, 2025 16:48:26
Managing issues in software development can be tedious and time-consuming. But what if your AI peer programmer could streamline this process for you? GitHub Copilot‘s latest issue management features can help developers create, organize, and even solve issues. Below, we’ll dig into these features and how they can save time, reduce friction, and maintain consistency across your projects.
1. Image to issue: Turn screenshots into instant bug reports
Writing detailed bug reports is often repetitive and frustrating, leading to inconsistent documentation. Copilot’s image to issue feature significantly reduces this friction.
Simply paste a screenshot of the bug into Copilot chat with a brief description prompt Copilot to create an issue for you, then Copilot will analyze the image and generate a comprehensive bug report for you. No more struggling to describe visual glitches or UI problems—the image will speak for itself, and Copilot will handle the documentation.
For example, if you encounter a UI alignment issue or a visual glitch that’s hard to describe, just capture a screenshot, paste it into Copilot, and briefly mention the problem. In the animation above, the user’s prompt was “create me a bug issue because markdown tables are not rendering properly in the comments.” Copilot then automatically drafted a report, including steps to reproduce the bug.
To get the most out of this feature, consider annotating your screenshots clearly—highlighting or circling the problematic area—to help Copilot generate even more precise issue descriptions.
Dive into the documentation to learn more.
2. Get the details right: Templates, tags, and types
Projects quickly become disorganized when team members skip adding proper metadata. Incorrect templates, missing labels, or wrong issue types make tracking and prioritization difficult.
Copilot solves this by automatically inferring the best template based on your prompt. It also adds appropriate labels and issue types without requiring you to navigate multiple dropdown menus or memorize tagging conventions.
Need something specific? Simply ask Copilot to add particular labels or switch templates. If you change templates after drafting, Copilot will automatically reformat your content—no manual copying required.
3. Stay organized with versioning and milestones
Keeping issues updated and properly categorized is crucial for clear communication, maintaining project velocity, and ensuring visibility into progress. But with so much else to do, it’s easy to let this work fall by the wayside.
With Copilot, adding projects and milestones is as simple as typing a prompt. You can also specify exactly how you want issues organized. For example, ask Copilot to use the “Bug Report” or “Feature Request” template, add labels like priority: high, frontend, or needs-triage, or set the issue type to “Task” or “Epic.” Copilot will apply these details automatically, ensuring your issues are consistently categorized.
Additionally, Copilot tracks all changes, making them easily referenceable. You can review issue history and revert changes if needed, ensuring nothing important gets lost.
4. Batch create multiple issues at once
Sometimes you need to log several issues after a customer meeting, user testing session, or bug bash. Traditionally, this means repeating the same creation process multiple times.
Copilot supports multi-issue drafting, allowing you to create multiple issues in a single conversation. Whether logging feature requests or documenting bugs, batch creation saves significant time.
Simply prompt Copilot to create the issues, describe each one, and Copilot will draft them all. For example, you could give the following prompt to create two issues at once:
Create me issues for the following features:
- Line breaks ignored in rendered Markdown despite double-space
- Bold and italic Markdown styles not applied when combinedYou will still need to review and finalize each one, but the drafting process is streamlined into a single workflow.
5. Let AI help fix your bugs with Copilot coding agent
Creating issues is only half the battle—fixing them is where the real work begins. You can now assign issues directly to Copilot. Just ask Copilot coding agent to take ownership of the issue, and your AI coding assistant will start analyzing the bug. Copilot can even suggest draft pull requests with potential fixes.
This seamless handoff reduces context-switching and accelerates resolution times, allowing your team to focus on more complex challenges.
Beyond Copilot: Issues enhancements on GitHub
While Copilot is already revolutionizing issue management, we at GitHub are always looking for ways to enhance the overall issues experience. For example, you can now:
- Standardize issue types across repositories for consistent tracking and reporting.
- Break down complex tasks into sub-issues for better progress management.
- Use advanced search capabilities with logical operators to quickly find exactly what you need.
- Manage larger projects with expanded limits supporting up to 50,000 items.
Kickstart enhanced issue management today
Ready to transform your issue management workflow with GitHub Copilot? Head to github.com/copilot and try prompts like:
- “Create me an issue for…”
- “Log a bug for…”
- Or simply upload a screenshot and mention you want to file a bug.
Experience firsthand how Copilot makes issue management feel less like administrative overhead and more like a conversation with your AI pair programmer.
Learn more about creating issues with Copilot >
The post 5 tips for using GitHub Copilot with issues to boost your productivity appeared first on The GitHub Blog.
June 17, 2025 16:43:28
The open source Git project just released Git 2.50 with features and bug fixes from 98 contributors, 35 of them new. We last caught up with you on the latest in Git back when 2.49 was released.
| 💡 Before we get into the details of this latest release, we wanted to remind you that Git Merge, the conference for Git users and developers is back this year on September 29-30, in San Francisco. Git Merge will feature talks from developers working on Git, and in the Git ecosystem. Tickets are on sale now; check out the website to learn more. |
With that out of the way, let’s take a look at some of the most interesting features and changes from Git 2.50.
Improvements for multiple cruft packs
When we covered Git 2.43, we talked about newly added support for multiple cruft packs. Git 2.50 improves on that with better command-line ergonomics, and some important bugfixes. In case you’re new to the series, need a refresher, or aren’t familiar with cruft packs, here’s a brief overview:
Git objects may be either reachable or unreachable. The set of reachable objects is everything you can walk to starting from one of your repository’s references: traversing from commits to their parent(s), trees to their sub-tree(s), and so on. Any object that you didn’t visit by repeating that process over all of your references is unreachable.
In Git 2.37, Git introduced cruft packs, a new way to store your repository’s unreachable objects. A cruft pack looks like an ordinary packfile with the addition of an .mtimes file, which is used to keep track of when each object was most recently written in order to determine when it is safe1 to discard it.
However, updating the cruft pack could be cumbersome–particularly in repositories with many unreachable objects–since a repository’s cruft pack must be rewritten in order to add new objects. Git 2.43 began to address this through a new command-line option: git repack --max-cruft-size. This option was designed to split unreachable objects across multiple packs, each no larger than the value specified by --max-cruft-size. But there were a couple of problems:
- If you’re familiar with
git repack’s--max-pack-sizeoption,--max-cruft-size’s behavior is quite confusing. The former option specifies the maximum size an individual pack can be, while the latter involves how and when to move objects between multiple packs. - The feature was broken to begin with! Since
--max-cruft-sizealso imposes on cruft packs the same pack-size constraints as--max-pack-sizedoes on non-cruft packs, it is often impossible to get the behavior you want.
For example, suppose you had two 100 MiB cruft packs and ran git repack --max-cruft-size=200M. You might expect Git to merge them into a single 200 MiB pack. But since --max-cruft-size also dictates the maximum size of the output pack, Git will refuse to combine them, or worse: rewrite the same pack repeatedly.
Git 2.50 addresses both of these issues with a new option: --combine-cruft-below-size. Instead of specifying the maximum size of the output pack, it determines which existing cruft pack(s) are eligible to be combined. This is particularly helpful for repositories that have accumulated many unreachable objects spread across multiple cruft packs. With this new option, you can gradually reduce the number of cruft packs in your repository over time by combining existing ones together.
With the introduction of --combine-cruft-below-size, Git 2.50 repurposed --max-cruft-size to behave as a cruft pack-specific override for --max-pack-size. Now --max-cruft-size only determines the size of the outgoing pack, not which packs get combined into it.
Along the way, a bug was uncovered that prevented objects stored in multiple cruft packs from being “freshened” in certain circumstances. In other words, some unreachable objects don’t have their modification times updated when they are rewritten, leading to them being removed from the repository earlier than they otherwise would have been. Git 2.50 squashes this bug, meaning that you can now efficiently manage multiple cruft packs and freshen their objects to your heart’s content.
Incremental multi-pack reachability bitmaps
Back in our coverage of Git 2.47, we talked about preliminary support for incremental multi-pack indexes. Multi-pack indexes (MIDXs) act like a single pack *.idx file for objects spread across multiple packs.
Multi-pack indexes are extremely useful to accelerate object lookup performance in large repositories by binary searching through a single index containing most of your repository’s contents, rather than repeatedly searching through each individual packfile. But multi-pack indexes aren’t just useful for accelerating object lookups. They’re also the basis for multi-pack reachability bitmaps, the MIDX-specific analogue of classic single-pack reachability bitmaps. If neither of those are familiar to you, don’t worry; here’s a brief refresher. Single-pack reachability bitmaps store a collection of bitmaps corresponding to a selection of commits. Each bit position in a pack bitmap refers to one object in that pack. In each individual commit’s bitmap, the set bits correspond to objects that are reachable from that commit, and the unset bits represent those that are not.
Multi-pack bitmaps were introduced to take advantage of the substantial performance increase afforded to us by reachability bitmaps. Instead of having bitmaps whose bit positions correspond to the set of objects in a single pack, a multi-pack bitmap’s bit positions correspond to the set of objects in a multi-pack index, which may include objects from arbitrarily many individual packs. If you’re curious to learn more about how multi-pack bitmaps work, you can read our earlier post Scaling monorepo maintenance.
However, like cruft packs above, multi-pack indexes can be cumbersome to update as your repository grows larger, since each update requires rewriting the entire multi-pack index and its corresponding bitmap, regardless of how many objects or packs are being added. In Git 2.47, the file format for multi-pack indexes became incremental, allowing multiple multi-pack index layers to be layered on top of one another forming a chain of MIDXs. This made it much easier to add objects to your repository’s MIDX, but the incremental MIDX format at the time did not yet have support for multi-pack bitmaps.
Git 2.50 brings support for the multi-pack reachability format to incremental MIDX chains, with each MIDX layer having its own *.bitmap file. These bitmap layers can be used in conjunction with one another to provide reachability information about selected commits at any layer of the MIDX chain. In effect, this allows extremely large repositories to quickly and efficiently add new reachability bitmaps as new commits are pushed to the repository, regardless of how large the repository is.
This feature is still considered highly experimental, and support for repacking objects into incremental multi-pack indexes and bitmaps is still fairly bare-bones. This is an active area of development, so we’ll make sure to cover any notable developments to incremental multi-pack reachability bitmaps in this series in the future.
[source]
The ORT merge engine replaces recursive
This release also saw some exciting updates related to merging. Way back when Git 2.33 was released, we talked about a new merge engine called “ORT” (standing for “Ostensibly Recursive’s Twin”).
ORT is a from-scratch rewrite of Git’s old merging engine, called “recursive.” ORT is significantly faster, more maintainable, and has many new features that were difficult to implement on top of its predecessor.
One of those features is the ability for Git to determine whether or not two things are mergeable without actually persisting any new objects necessary to construct the merge in the repository. Previously, the only way to tell whether two things are mergeable was to run git merge-tree --write-tree on them. That works, but in this example merge-tree wrote any new objects generated by the merge into the repository. Over time, these can accumulate and cause performance issues. In Git 2.50, you can make the same determination without writing any new objects by using merge-tree’s new --quiet mode and relying on its exit code.
Most excitingly in this release is that ORT has entirely superseded recursive, and recursive is no longer part of Git’s source code. When ORT was first introduced, it was only accessible through git merge’s -s option to select a strategy. In Git 2.34, ORT became the default choice over recursive, though the latter was still available in case there were bugs or behavior differences between the two. Now, 16 versions and two and a half years later, recursive has been completely removed from Git, with its author, Elijah Newren, writing:
As a wise man once told me, “Deleted code is debugged code!”
As of Git 2.50, recursive has been completely debugged deleted. For more about ORT’s internals and its development, check out this five part series from Elijah here, here, here, here, and here.
If you’ve ever scripted around your repository’s objects, you are likely familiar with
git cat-file, Git’s purpose-built tool to list objects and print their contents.git cat-filehas many modes, like--batch(for printing out the contents of objects), or--batch-check(for printing out certain information about objects without printing their contents).Oftentimes it is useful to dump the set of all objects of a certain type in your repository. For commits,
git rev-listcan easily enumerate a set of commits. But what about, say, trees? In the past, to filter down to just the tree objects from a list of objects, you might have written something like:$ git cat-file --batch-check='%(objecttype) %(objectname)' \
Git 2.50 brings Git’s object filtering mechanism used in partial clones to
--buffer <in | perl -ne 'print "$1\n" if /^tree ([0-9a-f]+)/'git cat-file, so the above can be rewritten a little more concisely like:$ git cat-file --batch-check='%(objectname)' --filter='object:type=tree' <in
[source]
- While we’re on the topic, let’s discuss a little-known
git cat-filecommand-line option:--allow-unknown-type. This arcane option was used with objects that have a type other thanblob,tree,commit, ortag. This is a quirk dating back a little more than a decade ago that allowsgit hash-objectto write objects with arbitrary types. In the time since, this feature has gotten very little use. In fact,git cat-file -p --allow-unknown-typecan’t even print out the contents of one of these objects!$ oid="$(git hash-object -w -t notatype --literally /dev/null)" $ git cat-file -p $oid fatal: invalid object type
This release makes the
--allow-unknown-typeoption silently do nothing, and removes support from git hash-object to write objects with unknown types in the first place.[source]
The
git maintenancecommand learned a number of new tricks this release as well. It can now perform a few new different kinds of tasks, likeworktree-prune,rerere-gc, andreflog-expire.worktree-prunemirrorsgit gc’s functionality to remove stale or broken Git worktrees.rerere-gcalso mirrors existing functionality exposed viagit gcto expire oldrerereentries from previously recorded merge conflict resolutions. Finally,reflog-expirecan be used to remove stale unreachable objects from out of the reflog.git maintenancealso ships with new configuration for the existingloose-objectstask. This task removes lingering loose objects that have since been packed away, and then makes new pack(s) for any loose objects that remain. The size of those packs was previously fixed at a maximum of 50,000, and can now be configured by themaintenance.loose-objects.batchSizeconfiguration.If you’ve ever needed to recover some work you lost, you may be familiar with Git’s reflog feature, which allows you to track changes to a reference over time. For example, you can go back and revisit earlier versions of your repository’s main branch by doing
git show main@{2}(to showmainprior to the two most recent updates) ormain@{1.week.ago}(to show where your copy of the branch was at a week ago).Reflog entries can accumulate over time, and you can reach for
git reflog expirein the event you need to clean them up. But how do you delete the entirety of a branch’s reflog? If you’re not yet running Git 2.50 and thought “surely it’sgit reflog delete”, you’d be wrong! Prior to Git 2.50, the only way to delete a branch’s entire reflog was to dogit reflog expire $BRANCH --expire=all.In Git 2.50, a new
deletesub-command was introduced, so you can accomplish the same as above with the much more naturalgit reflog delete $BRANCH.[source]
Speaking of references, Git 2.50 also received some attention to how references are processed and used throughout its codebase. When using the low-level
git update-refcommand, Git used to spend time checking whether or not the proposed refname could also be a valid object ID, making its lookups ambiguous. Sinceupdate-refis such a low-level command, this check is no longer done, delivering some performance benefits to higher-level commands that rely onupdate-reffor their functionality.Git 2.50 also learned how to cache whether or not any prefix of a proposed reference name already exists (for example, you can’t create a reference
ref/heads/foo/bar/bazif eitherrefs/heads/foo/barorrefs/heads/fooalready exists).Finally, in order to make those checks, Git used to create a new reference iterator for each individual prefix. Git 2.50’s reference backends learned how to “seek” existing iterators, saving time by being able to reuse the same iterator when checking each possible prefix.
[source]
If you’ve ever had to tinker with Git’s low-level curl configuration, you may be familiar with Git’s configuration options for tuning HTTP connections, like
http.lowSpeedLimitandhttp.lowSpeedTimewhich are used to terminate an HTTP connection that is transferring data too slowly.These options can be useful when fine-tuning Git to work in complex networking environments. But what if you want to tweak Git’s TCP Keepalive behavior? This can be useful to control when and how often to send keepalive probes, as well as how many to send, before terminating a connection that hasn’t sent data recently.
Prior to Git 2.50, this wasn’t possible, but this version introduces three new configuration options:
http.keepAliveIdle,http.keepAliveInterval, andhttp.keepAliveCountwhich can be used to control the fine-grained behavior of curl’s TCP probing (provided your operating system supports it).[source]
Git is famously portable and runs on a wide variety of operating systems and environments with very few dependencies. Over the years, various parts of Git have been written in Perl, including some commands like the original implementation of
git add -i. These days, very few remaining Git commands are written in Perl.This version reduces Git’s usage of Perl by removing it as a dependency of the test suite and documentation toolchain. Many Perl one-liners from Git’s test suite were rewritten to use other Shell functions or builtins, and some were rewritten as tiny C programs. For the handful of remaining hard dependencies on Perl, those tests will be skipped on systems that don’t have a working Perl.
-
This release also shipped a minor cosmetic update to
git rebase -i. When starting a rebase, your$EDITORmight appear with contents that look something like:pick c108101daa foo pick d2a0730acf bar pick e5291f9231 baz
You can edit that list to
break,reword, orexec(among many others), and Git will happily execute your rebase. But if you change the commit message in your rebase’s TODO script, they won’t actually change!That’s because the commit messages shown in the TODO script are just meant to help you identify which commits you’re rebasing. (If you want to rewrite any commit messages along the way, you can use the
rewordcommand instead). To clarify that these messages are cosmetic, Git will now prefix them with a#comment character like so:pick c108101daa # foo pick d2a0730acf # bar pick e5291f9231 # baz
[source]
Long time readers of this series will recall our coverage of Git’s
bundlefeature (when Git added support for partial bundles), though we haven’t covered Git’sbundle-urifeature. Git bundles are a way to package your repositories contents: both its objects and the references that point at them into a single*.bundlefile.While Git has had support for bundles since as early as v1.5.1 (nearly 18 years ago!), its
bundle-urifeature is much newer. In short, thebundle-urifeature allows a server to serve part of a clone by first directing the client to download a*.bundlefile. After the client does so, it will try to perform a fill-in fetch to gather any missing data advertised by the server but not part of the bundle.To speed up this fill-in fetch, your Git client will advertise any references that it picked up from the
*.bundleitself. But in previous versions of Git, this could sometimes result in slower clones overall! That’s because up until Git 2.50, Git would only advertise the branches inrefs/heads/*when asking the server to send the remaining set of objects.Git 2.50 now includes advertises all references it knows about from the
*.bundlewhen doing a fill-in fetch on the server, makingbundle-uri-enabled clones much faster.For more details about these changes, you can check out this blog post from Scott Chacon.
[source]
Last but not least,
git add -p(andgit add -i) now work much more smoothly in sparse checkouts by no longer having to expand the sparse index. This follows in a long line of work that has been gradually adding sparse-index compatibility to Git commands that interact with the index.Now you can interactively stage parts of your changes before committing in a sparse checkout without having to wait for Git to populate the sparsified parts of your repository’s index. Give it a whirl on your local sparse checkout today!
[source]
The rest of the iceberg
That’s just a sample of changes from the latest release. For more, check out the release notes for 2.50, or any previous version in the Git repository.
🎉 Git turned 20 this year! Celebrate by watching our interview of Linus Torvalds, where we discuss how it forever changed software development.
1 It’s never truly safe to remove an unreachable object from a Git repository that is accepting incoming writes, because marking an object as unreachable can race with incoming reference updates, pushes, etc. At GitHub, we use Git’s –expire-to feature (which we wrote about in our coverage of Git 2.39) in something we call “limbo repositories” to quickly recover objects that shouldn’t have been deleted, before deleting them for good. ↩️
The post Highlights from Git 2.50 appeared first on The GitHub Blog.
June 30, 2025 22:24:42
One of the beautiful things about software is that it’s always evolving. However, each piece carries the weight of past decisions made when it was created. Over time, quick fixes, “temporary” workarounds, and deadline compromises compound into tech debt. Like financial debt, the longer you wait to address it, the more expensive it becomes.
It’s challenging to prioritize tech debt fixes when deadlines loom and feature requests keep streaming in. Tech debt work feels like a luxury when you’re constantly in reactive mode. Fixing what’s broken today takes precedence over preventing something from possibly breaking tomorrow. Occasionally that accumulated tech debt even results in full system rewrites, which are time-consuming and costly, just to achieve parity with existing systems.
Common approaches to managing tech debt, like gardening weeks (dedicated sprints for tech debt) and extended feature timelines, don’t work well. Gardening weeks treat tech debt as an exception rather than ongoing maintenance, often leaving larger problems unaddressed while teams postpone smaller fixes. Extended timelines create unrealistic estimates that can break trust between engineering and product teams.
The fundamental problem is treating tech debt as something that interrupts normal development flow. What if instead you could chip away at tech debt continuously, in parallel with regular work, without disrupting sprint commitments or feature delivery timelines?
Using AI agents to routinely tackle tech debt
Managing tech debt is a big opportunity for AI agents like the coding agent in GitHub Copilot.
With AI agents like the coding agent in GitHub Copilot, tech debt items no longer need to go into the backlog to die. While you’re focusing on the new features and architectural changes that you need to bring to your evolving codebase, you can assign GitHub Copilot to complete tech debt tasks at the same time.
Here are some examples of what the coding agent can do:
- Improve code test coverage: Have limited code testing coverage but know you’ll never get the buy-in to spend time writing more tests? Assign issues to GitHub Copilot to increase test coverage. The agent will take care of it and ping you when the tests are ready to review.
- Swap out dependencies: Need to swap out a mocking library for a different one, but know it will be a long process? Assign the issue to swap out the library to GitHub Copilot. It can work through that swap while you’re focusing your attention elsewhere.
- Standardize patterns across codebases: Are there multiple ways to return and log errors in your codebase, making it hard to investigate issues when they occur and leading to confusion during development? Assign an issue to GitHub Copilot to standardize a single way of returning and logging errors.
- Optimize frontend loading patterns: Is there an area where you are making more API calls than your application really needs? Ask GitHub Copilot to change the application to only make those API calls when the data is requested, instead of on every page load.
- Identify and eliminate dead code: Is there anywhere in your project where you may have unused functions, outdated endpoints, or stale config hanging out? Ask GitHub Copilot to look for these and suggest ways to safely remove them.
If those examples sound very specific, it’s because they are. These are all real changes that my team has tackled using GitHub Copilot coding agent—and these changes probably wouldn’t have occurred without it. The ability for us to tackle tech debt continuously while delivering features has grown exponentially, and working AI agents into our workflow has proven to be incredibly valuable. We’ve been able to reduce the time it takes to remove tech debt from weeks of intermittent, split focus to a few minutes of writing an issue and a few hours reviewing and iterating on a pull request.
This isn’t about replacing human engineers; it’s about amplifying what we do best. While agents handle the repetitive, time-consuming work of refactoring legacy code, updating dependencies, and standardizing patterns across codebases, we can focus on architecture decisions, feature innovation, and solving complex business problems. The result is software that stays healthier over time, teams that ship faster, and engineers who spend their time on work that actually energizes them.
When AI is your copilot, you still have to do the work
The more I learn about AI, the more I realize just how critical humans are in the entire process. AI agents excel at well-defined, repetitive tasks, the kind of tech debt work that’s important but tedious. But when it comes to larger architectural decisions or complex business logic changes, human judgment is still irreplaceable.
Since we are engineers, we know the careful planning and tradeoff considerations that come with our craft. One wrong semicolon, and the whole thing can come crashing down. This is why every prompt requires careful consideration and each change to your codebase requires thorough review.
Think of it as working with a brilliant partner that can write clean code all day but needs guidance on what actually matters for your application. The AI agent brings speed and consistency; it never gets tired, never cuts corners because it’s Friday afternoon, and can maintain focus across hundreds of changes. But you bring the strategic thinking: knowing which tech debt to tackle first, understanding the business impact of different approaches, and recognizing when a “quick fix” might create bigger problems down the line.
The magic happens in the interaction between human judgment and AI execution. You define the problem, set the constraints, and validate the solution. The agent handles the tedious implementation details that would otherwise consume hours of your time. This partnership lets you operate at a higher level while still maintaining quality and control.
Tips to make the most of the coding agent in GitHub Copilot
Here’s what I’ve learned from using the coding agent in GitHub Copilot for the past few months:
- Write Copilot Instructions for your repository. This results in a much better experience. You can even ask your agent to write the instructions for you to get started, which is how I did it! Include things like the scripts that you need to run during development to format and lint (looking at you,
go fmt). - Work in digestible chunks. This isn’t necessarily because the agent needs to work in small chunks. I learned the hard way that it will make some pretty ambitious, sweeping changes if you don’t explicitly state which areas of your codebase you want changed. However, reviewing a 100+-file pull request is not my idea of a good time, so working in digestible chunks generally makes for a better experience for me as the reviewer. What this looks like for me is instead of writing an issue that says “Improve test coverage for this application”, I create multiple issues assigned to GitHub Copilot that “improve test coverage for file X” or “improve test coverage for folder Y”, to better scope the changes that I need to review.
- Master the art of effective prompting. The quality of what you get from AI agents depends heavily on how well you communicate your requirements. Be specific about the context, constraints, and coding standards you want the agent to follow.
- Always review the code thoroughly. While AI agents can handle repetitive tasks well, they don’t understand business logic like you do. Making code review a central part of your workflow ensures quality while still benefiting from the automation. This is one of the reasons why I love the GitHub Copilot coding agent. It uses the same code review tools that I use every day to review code from my colleagues, making it incredibly easy to fit into my workflow.
The future belongs to software engineers who embrace AI tools
We’re at a pivotal moment in software engineering. For too long, tech debt has been the silent productivity killer. It’s the thing we all know needs attention but rarely gets prioritized until it becomes a crisis. AI coding agents are giving us the opportunity to change that equation entirely.
The engineers who learn to effectively collaborate with AI agents—the ones who master the art of clear prompting, thoughtful code review, and strategic task delegation—will have a massive advantage. They’ll be able to maintain codebases that their peers struggle with, tackle tech debt that others avoid, and potentially eliminate the need for those expensive, time-consuming rewrites that have plagued our industry for decades.
But this transformation requires intentional effort. You need to experiment with these tools, learn their strengths and limitations, and integrate them into your workflow. The technology is ready; the question is whether you’ll take advantage of it.
If you haven’t started exploring how AI agents can help with your tech debt, now is the perfect time to begin. Your future self, who is more productive, less frustrated, and focused on the creative aspects of engineering, will thank you. More importantly, so will your users, who’ll benefit from a more stable, well-maintained application that continues to evolve instead of eventually requiring significant downtime for a complete rebuild.
Assign your tech debt to GitHub Copilot coding agent in your repositories today!
The post How the GitHub billing team uses the coding agent in GitHub Copilot to continuously burn down technical debt appeared first on The GitHub Blog.
June 11, 2025 23:24:42
In May, we experienced three incidents that resulted in degraded performance across GitHub services.
May 1 22:09 UTC (lasting 1 hour and 4 minutes)
On May 1, 2025, from 22:09 UTC to 23:13 UTC, the Issues service was degraded and users weren’t able to upload attachments. The root cause was identified to be a new feature which added a custom header to all client-side HTTP requests, causing CORS errors when uploading attachments to our provider. We estimate that ~130k users were impacted by the incident for ~45min.
We mitigated the incident by rolling back the feature flag that added the new header at 22:56 UTC. In order to prevent this from happening again, we are adding new metrics to monitor and ensure the safe rollout of changes to client-side requests. We have since deployed an augmented version of the feature based on learnings from this incident that is performing well in production.
May 28 09:45 UTC (lasting 5 hours)
On May 28, 2025, from approximately 09:45 UTC to 14:45 UTC, GitHub Actions experienced delayed job starts for workflows in public repos using Ubuntu-24 standard hosted runners. This was caused by a misconfiguration in backend caching behavior after a failover, which led to duplicate job assignments reducing overall capacity in the impacted hosted runner pools. Approximately 19.7% of Ubuntu-24 hosted runner jobs on public repos were delayed. Other hosted runners, self-hosted runners, and private repo workflows were unaffected.
By 12:45 UTC, the configuration issue was fixed through updates to the backend cache. The pools were also scaled up to more quickly work through the backlog of queued jobs until queuing impact was fully mitigated at 14:45 UTC. We are improving failover resiliency and validation to reduce the likelihood of similar issues in the future.
May 30 08:10 UTC (lasting 7 hours and 50 minutes)
On May 30, 2025, between 08:10 UTC and 16:00 UTC, the Microsoft Teams GitHub integration service experienced a complete service outage.
During this period, the integration was unable to process user requests or deliver notifications, resulting in a 100% error rate across all functionality, with the exception of link previews. This outage was caused by an authentication issue with our downstream authentication provider.
While the appropriate monitoring was in place, the alerting thresholds were not sufficiently sensitive to trigger a timely response, resulting in a delay in incident detection and engagement. Once engaged, our team worked closely with the downstream provider to diagnose and resolve the authentication failure. However, longer-than-expected response times from the provider contributed to the extended duration of the outage.
We mitigated the incident by working with our provider to restore service functionality and are working to migrate to more durable authentication methods to reduce the risk of similar issues in the future.
Please follow our status page for real-time updates on status changes and post-incident recaps. To learn more about what we’re working on, check out the GitHub Engineering Blog.
The post GitHub Availability Report: May 2025 appeared first on The GitHub Blog.